了解大规模生产系统中
Reported As "SSD-Related"(RASR)故障的特点和潜在的根本影响因素,以及SSD的这些错误与系统设计和使用之间的因果关系,为硬件架构师、软件工程师和系统管理员提供一些主要的经验教训以及实际的补救措施。发于ATC 2019,原文链接
SSD中的错误非常复杂并且受各种因素的影响,本文是阿里公司团队研究的,实验部署在7个阿里云数据中心450000块SSD上并耗时3年。通过在集群节点上配置系统监管的守护进程来捕获异常行为,这些守护进程自动监视从硬件到软件的系统组件的健康状况,并定期或者事件发生时进行日志记录:
- 系统启动时检查BIOS消息
- 运行时检查内核syslog
- 检查云服务的功能和可用性
在发生异常事件时,守护进程将报告带有时间戳、所涉及的组件和相应的日志片段
本文所研究的数据集包含上述守护进程收集的故障信息、Smart Log以及修复日志
RASR故障特征
收集的与硬件相关的150K failure tickets中有5.6%是RASR错误,主要表现为 Node Unbootable, File System Unmountable, Drive Unfound, Buffer IO Error, and Media Error

通过将RASR故障与修复日志相关联,发现RASR故障中有很大一部分(34.4%)不是由SSD设备引起的。
比如,将SSD插入错误的驱动器插槽,这是一个典型的人为错误,像这样的人为错误占RASR故障的20.1%。
并且设备的位置以及云服务的类型等都会对SSD错误有所影响
为了了解RASR故障产生的根本原因,将从硬件层面、软件层面以及系统管理方面深入研究
Lessons and Actions for Hardware Architects
从硬件的角度来看,主要的影响因素为节点内SSD堆叠和机架内节点的放置
整个架构如下:
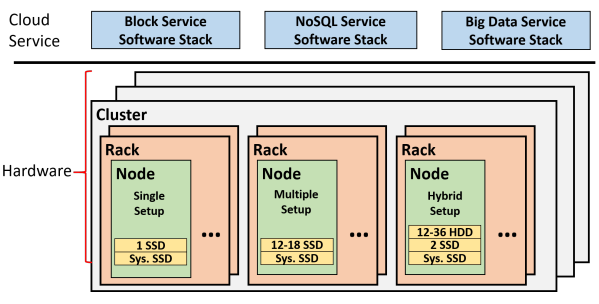
有三种不同类型的节点配置:
Single setup: 每个节点存放一块SSD,用来存储临时数据
Multiple setup:每个节点包含了12-18块SSD,用来做持久化存储
Hybrid setup:每个节点包含了2块SSD和12-36块HDD,其中这2块SSD用来缓存写入
此外,每个节点都有一块SSD作为系统驱动盘
每一个机架(Rack)由16到48个节点组成,DFS集群跨越12到18个机架。
在DFS之上,系统支持三种类型的云服务,包括Block服务、NoSQL服务和Big Data服务。
文中也研究了RASR错误和其他重要因素的关联性,比如上述的云服务类型、不同的SSD模型、在数据中心的位置
实验显示,模型对RASR错误的影响不大;三种云服务模式中的块服务模式对RASR错误影响最大;放置在不同的数据中心对RASR中不同错误的影响大小是不同的
这张图显示的是一个节点内部的结构:

由于Arrhenius定律,NAND闪存在较高温度下是不可靠的,将导致出错率上升。而SSD放置可能会影响节点和机架中的气流,进而影响相邻SSD的工作温度,导致异常行为的发生,这就是passive heating(被动加热)
被动加热主要来源于三方面:
- Hot Airflow:在每个节点内部,左边产生冷空气流,经过前中后位置的SSD,从出风口出来的空气一般为热空气,那么处在后面的空闲SSD可能接收到被前面高负载SSD加热的空气流,从而导致升温
- Hot Neighbor:被邻居高负载SSD接触加热
- Hot Air Recirculation: 当一个节点从机架中移走时,形成的空节点槽,易形成隧道热气流,从而影响周边SSD的温度
然而随着SSD温度的上升,将导致位错误率也随之上升。实验发现温度和位错误率的关系如下图所示:
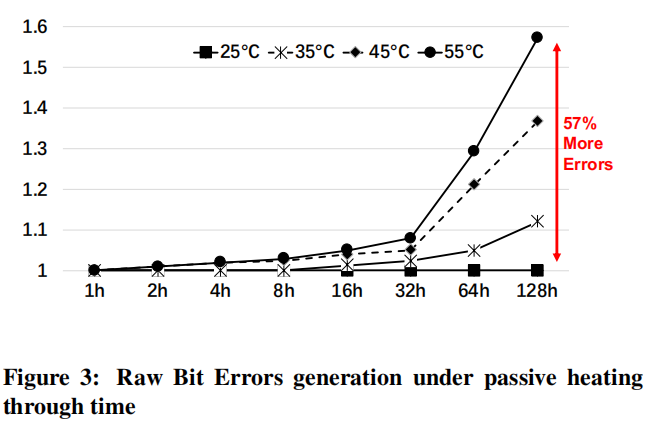
在55℃下测试128小时后,错误率可上升至57%!!
解决办法:
- data scrubbing
- read refresh,SSD中的FTL通常具有读取刷新机制,以校正位错误并在读取期间重新分配数据。采用scanning的方式周期性扫描,来追踪读取刷新。实验发现每4个小时扫描一次可以有效控制位错误率
虽然通过常规扫描触发读取刷新有助于抵消被动加热的影响,但在生产系统上直接部署它还存在其他潜在问题:
-
首先,常规扫描需要
细粒度的温度监测来检测被动加热。目前,可以通过查询Smart日志来获得SSD的温度。在我们的生产系统中,Smart日志每天都被拉出来,这不足以监测被动加热(实验测得4小时扫描一次效果最好)。提高查询速率需要对分布式监视守护进程进行更改,并可能影响服务质量。虽然一些物理传感器可以检测硬件温度,但是要加到系统有难度 -
扫描可能会带来更多的
读干扰错误。尽管扫描不必每4小时读取整个盘(比如只需要扫描存储数据的地方)或每4小时盲目执行一次(比如只有当SSD处于被动加热(超过4小时)时的区域), 由于读取或多或少会受到干扰,SSD仍可能受到越来越多的设备错误的影响。因此,虽然有效,但很难直接将实验中的常规扫描应用于生产系统 -
另外,也可以在供应商的支持下
实现在FTL中检测和修复被动加热的技术- 许多固态硬盘支持FTL中的热限制,这意味着该设备已经密切监控了温度
- FTL非常清楚哪些部分的数据具有高错误率,因此可以通过主动读取刷新相应的数据来相应地作出反应
因此,基于FTL的解决方案可能更有效
Lessons and Actions for Software Engineers
由于过度使用SSD导致位错误率上升,分析了块服务中的不平衡使用、不平衡的根本原因以及如何缓解不平衡使用
服务软件栈中的数据分配方案和云服务中的I/O模式对SSD可靠性和RASR错误起着非常重要的作用
比如,块服务由基于直接映射的数据分配方案授权,在类似HDFS的分布式文件系统(DFS)之上运行时,可能会导致SSD使用的严重不平衡:15%-20%的SSD被过度使用,使设备错误增加了77.3%,器件故障率提高了18.7%。
实验比较过度使用的SSD和平均使用的SSD区别,根据二八定律,在块服务中20%的SSD被标记为过度使用,其余标记为平均使用:

实验发现,过度使用的SSD出错概率更高
使用不平衡的根本原因:(1)更新策略;(2)用户I/O模式

- 左边灰色部分是未更新的映射表,表示在SSD1中存放了编号为Chunk1的块。右边是软件堆栈查询映射表并将更新的块写入相同的SSD(即“SSD 1”上的“Updated chunk1”),这种方式是
就地更新 - 块服务接收到来自不同用户的I/O请求,而有的用户更新非常频繁,有的则不是
上述就地更新和多样化的更新策略导致块服务下SSD的不平衡使用
另外两种服务模式,NoSQL和Big Data?
与块服务不同,其他两个云服务不会造成严重的使用不平衡,因为它们有不同的更新策略或I/O模式
特别地,NoSQL服务将小更新合并在一起,并且总是为更新的数据生成一个新的chunk,这样可以映射到不同的SSD。
在Big Data服务中,更新频率低,读取和添加新数据的频率要高得多
因此,在NoSQL和Big Data服务下,SSD使用较为平衡
缓解不平衡使用的方法:添加一个shared append-only log,与原先方法不同的是这个块现在保存在一个日志中,日志将最新的更新附加到它的末尾
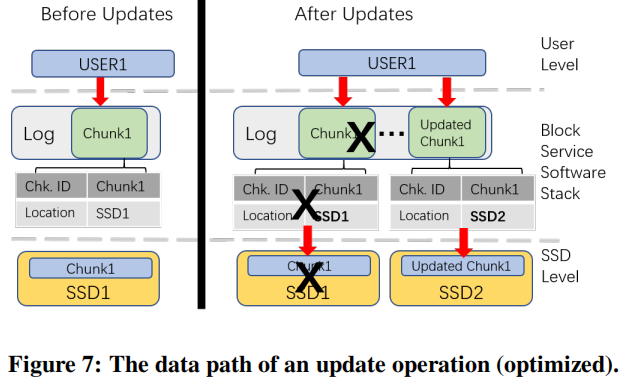
在接收到更新后,软件堆栈将做了以下三步:
- 前一个块(标记为“X”)无效
- 将更新附加到日志中
- 更改映射表将更新的块映射到新的SSD(SSD 2)
在GC的时候,这些被标记的无效块将被回收
通过这种方式,减缓了SSD之间的使用差异,因为每个更新的块将根据可用驱动器之间的磨损情况分配。当然,在某些情况下,如果原始SSD恰好是最合适的候选块,更新的块可能仍然映射到原始SSD
Lessons and Actions for System Administrators
观察到并不是所有的RASR错误都是SSD出错引起的,非SSD出错来源主要是(1)人为错误(2)互连故障
其中,人为错误导致RASR故障的20.5%,包括将设备插入错误的插槽(“时隙检查”)和不正确的配置(“安装选项检查”)
由更换电缆修复的故障互连线(电缆接线接错了),在SSD之外,占RASR故障的13.9%。
注意,虽然“替换SSD”占RASR故障的31.2%,但由于设备和人工的高成本,我们仍然将其作为修复策略的最后手段。
因此,我们感兴趣的是,人为错误和错误的相互连接是否可以快速诊断或在很大程度上避免。
解决办法:
1.互连故障
要解决由互连故障引起的RASR故障(驱动器未发现),更换SSD与主机之间的电缆是一种有效的方法。
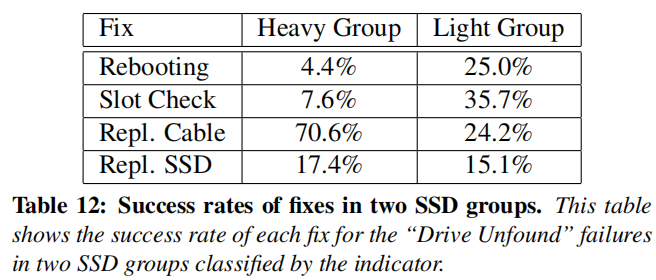
从上述图中可以看到,对于Heavy Group和Light Group,不同的修复策略成功率不同。对于Heavy Group下更换电缆的成功率为70.6%,这个结果表明,如果我们直接更换受到错误严重影响的驱动器的电缆,就可以大大提高第一次尝试的成功率。
2.人为错误
SSD有三种不同的用途:系统驱动、存储、缓存
但是使用的都是同一种接口,从而人为插错插槽的概率很高,因此本文提出One Interface One Purpose (OIOP),对不同用途的SSD可以使用不同的接口,例如,U2/M.2用于系统驱动器,SATA用于存储
除了OIOP之外,另一个可能的解决方案是使用状态灯来区分驱动器的功能。
“I want to say”
这篇文章主要分析了在分布式架构下,与SSD相关的错误类型,并从硬件、软件以及系统管理员角度进行对其进行研究,分析错误产生的原因以及可以参考的经验。
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
good luck!