Flash-Level INterference-aware scheduler
分析Multi-Queue引起的不公平是由于应用之间存在干扰所致,分析干扰来源,提出干扰感知调度器FLIN。在SSD控制器内将事务重新排序,平衡并发应用之间的推进速度,实现fairness,原文链接
写在文前
在NVMe SSD中,使用了Multi-Queue,使得SSD可以跨过块设备层直接访问应用层I/O请求队列。虽然这大大提升了性能,但是由于没有经过块设备层(没有了OS soft stack)导致应用之间的unfairness
最近在看的博文都是关于NVMe SSD中使用Multi-Queue引起的公平性问题,可以参考之前的博文:
Multi-Queue Fair Queuing
SSD Organization
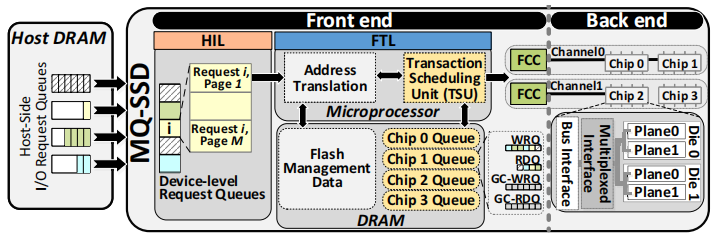
主要分为两个部分,front end 和 back end,其中front end主要是由控制和通信单元组成;back end主要是由数据存储单元组成。由这两部分来处理以物理页为大小的I/O事务(包括读、写、擦除)
back end部分比较容易理解,由多个channel组成,所谓channel也就是请求总线。每个channel连接到底层存储器的一个或多个chip(例如NAND闪存)。每个chip可以由一个或多个die(晶元)组成。每个die又可以由一个或多个plane(晶片)组成。plane之间可以并发地处理I/O事务
front end管理back end中的资源,并负责将I/O事务发送到channels。由三部分组成:
- HIL(host-interface logic):负责和host进行通信,并采用RR仲裁方式从主机请求队列中取请求到device-level请求队列
- FTL(flash translation layer):使用嵌入式处理器和DRAM管理SSD资源和进程I/O请求
- FCCs(flash channel controllers):用于前端和后端channel之间的通信
处理I/O请求的7个步骤
- host产生一个I/O请求,并将此I/O请求插入到主机端专用的DRAM I/O队列,也就是所谓的内存队列中。每个队列都对应着一个I/O流,可以看到图中用不同颜色表示,并且每个队列中的请求数目不一定相同
- MQ-SSD中的HIL从主机端队列获取请求,并将其插入到SSD中的设备级队列中。(原先是RR仲裁方式,也即是每个队列一次取一个请求,保证绝对的公平。)
- HIL解析请求并将其分解为多个事务(每个事务的大小是以物理页为单位的)
- Address Translation将事务的逻辑地址转化为物理地址
- TSU(transaction scheduling unit)进行事务调度,并将事务放在chip-level队列中,也就是说到这一步已经确定了当前事务放在那个chip上进行处理
- TSU从chip-level选一个事务,并将其发送到相应的FCC
- FFC发送命令给目标chip来执行当前事务
GC步骤
- 根据无效页数目标记要被擦除的block
- 产生读/写事务,将待擦除块中的有效页移到别的空闲位置
- 对一次block擦除产生一个erase事务
TSU负责调度I/O事务和GC事务
- 对于I/O事务,它为每个chip在DRAM中维护一个读队列(RDQ)和一个写队列(WRQ)。
- GC事务保存在DRAM中的一组单独的读(GC-RDQ)和写(GC-WRQ)队列中。
TSU通常采用先到先得的事务调度策略,并通常将I/O事务优先于GC事务。当然为了更好的使用闪存的并行性,也有的TSU对其进行了部分重新排序
四种干扰
由于缺乏公平的调度机制和并发应用之间存在的干扰,导致应用之间的不公平,这篇文章分析了对于每个flow,导致不公平性的四种干扰来源, (1) the intensity of requests sent by each application, (2) differences in request access patterns, (3) the ratio of reads to writes, (4) garbage collection
1.Flows with Different I/O Intensities
I/O密集性指的是产生I/O事务的速率,这取决于到达时间和I/O请求的大小(因为较大的I/O请求产生更多的页面大小的事务),也就是一个请求可以解析成多个子请求来处理。
transaction turnaround time: 对于每个事务的处理时间可以包括三个部分:1)chip-level队列当中的等待时间 2)前后端之间的传输时间 3)执行事务所需的时间
当I/O强度增加的时候,在队列中的排队时间将会增大,而且队列长度越长,事务的等待时间也就越长。
因此,当两个不同I/O密集度的流并发执行时,对于每个流而言,平均队列长度增加,而且这对低强度的流影响更大。低强度流的平均响应时间由于高强度流的干扰而大幅度增加。
文中通过基流和干扰流的不同强度来做实验。
2.Flows with Different Access Patterns
流的访问模式决定了它的事务如何分布在芯片级队列中,有的流在chip上处理分布比较均匀,充分利用了闪存的并行性,而有的流分布不均匀。
访问模式取决于流中每个请求的起始地址和大小。
具有并行友好访问模式的流容易受到不利用并行性的访问模式流的干扰。
3.Flows with Different Read/Write Ratios
为了实现读优先,TSUs主要采用两种方式:1)读队列中的事务总是比写队列中优先处理 2)写事务可以被读事务抢占
问题:增加了写事务的等待时间,减慢了写事务流
结论:当并发运行的流具有不同的读/写比时,现有的调度策略在提供公平性方面不是有效的。
4.Flows with Different GC Demands
GC的调用速度主要取决于流的写入强度和访问模式。导致GC频繁调用的流(高GC)会不成比例地减慢不调用GC的并发运行流(低GC)。
首先,GC频繁度随写强度的增加成正比的增加。第二,随着干扰流的写入强度增加,触发更多的GC操作,公平性降低。第三,当基流的GC需求与干扰流的GC需求之差增大时,非抢占式GC导致基流更大的减速,降低公平性。第四,与非抢占式GC相比,半抢占式SPGC提高了公平性,但只提高了少量的公平性,因为当有大量挂起的写操作时,SPGC禁止抢占。
所谓半抢占式是指当空闲资源数目在硬阈值以上时,允许用户请求抢占GC操作
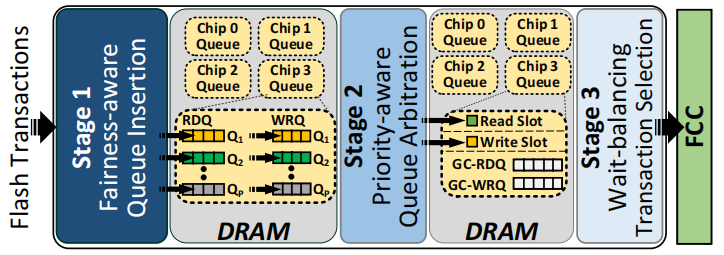
FLIN
一种新的基于多队列的闪存调度单元,调度并重排序事务以减少干扰。
由三阶段组成:
-
fairness-aware queue insertion
事务插入队列的位置取决于与事务对应的流的当前强度和访问模式,例如(1)低优先级流减慢速度不会表现出不公平,(2)能够利用后端并行性的流不易受到干扰 -
priority-aware queue arbitration
使用主机分配给每个流的优先级级别来确定每个后端内存芯片的下一个读取请求和下一个写入请求。
仲裁的目的是确保分配给同一优先级别流同样的处理速度
- wait-balancing transaction selection
选择事务发送给FCCs缓解读写比率差异和垃圾收集带来的干扰
为此,调度程序选择分派读事务、写事务或垃圾收集事务,其方式是(1)平衡读事务的放缓和写事务的放缓,以及(2)在所有流中公平地分配垃圾收集事务的开销。
1.Fairness-Aware Queue Insertion
以缓解由于并发运行流的强度和访问模式而产生的干扰。
由于在第一阶段并未处理优先级问题,因此FLIN为每个流优先级维护每个chip单独的读写队列(分别为图中的RDQ和WRQ)
使用启发式O(t)算法确定每个事务被插入到与事务访问类型(即读或写)和优先级别对应的队列中,限制第一阶段所需的时间,并将所花费的事务周转时间的比例降到最低
启发式算法的三个关键点:
- 当高强度流插入许多事务时,低强度流的性能对增加的队列长度非常敏感
- 根据应用程序的当前阶段,某些流会在高强度和低强度之间发生变化
- 当并行性较差的流将请求插入某些(但不是全部)芯片级队列时,利用后端并行性的流中的一些(但不是全部)也会遇到高队列等待时间

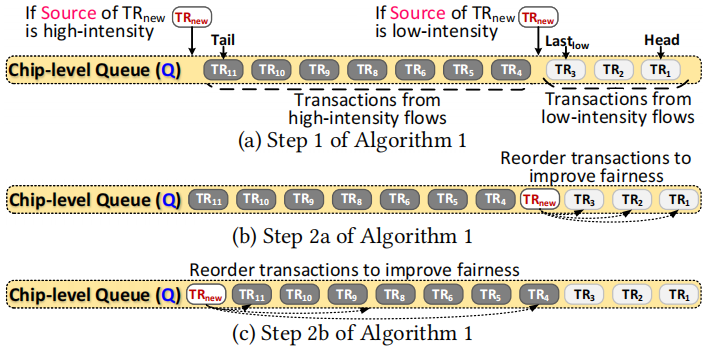
步骤1:优先考虑低强度流
来自低强度流的事务总是优先于来自高强度流的事务。
如果TRNew来自低强度流,则启发式在Lastlow之后立即将TRNew插入到队列中。
步骤2a:最大限度地提高低强度流之间的公平性
启示法首先估计,如果流单独运行,TRNew需要等待多长时间才能得到服务。此估计值还用于确定事务的减速,并与队列中的事务一起保存
为了公平起见,启发式重新排序了队列中低强度流的事务。此重新排序步骤优先处理一个事务(即,将其移动到更接近队列头的位置),这意味着它的源流要么(1)强度较低,要么(2)更好地利用MQ-SSD后端提供的并行性
步骤2b:最大限度地提高高强度流之间的公平性
在将新的高强度事务插入队列后,启发式检查当前公平性(第18行)。
将当前的fairness和预定阈值Fthr比较,如果小于Fthr并且新事务属于最大减速的流,启发式将事务移动到所有其他高强度流事务之前。
这种方法通常可以帮助正在从低强度向高强度过渡的流,因为这种流特别容易受到其他高强度流的干扰。如果公平高于阈值,这意味着所有高强度流都得到了某种程度的公平对待,则启发式只会重新排序高强度流事务以实现公平。(fairness越高越公平)
2.Priority-Aware Queue Arbitration
在第一阶段只考虑了流强度和访问模式,并没有考虑优先级,因此在第二阶段就需要把优先级考虑进去
许多主机接口协议,如NVMe,允许主机为每个流分配不同的优先级。
FLIN为每个优先级级别维护一个读和写队列,也就是说优先级别为p的话,那么对于每个chip,维护p个读队列和p个写队列,那么阶段2这种方式就是选取p读队列头部的一个事务和p写队列头部的一个事务,然后,将这两个事务发送到第三阶段
如果超过一个队列准备好了事务发送到下一个阶段,那么采用weight RR仲裁方式
如果协议定义了P优先级级别,其中0级是最低优先级,P-1级别是最高优先级,将权重 $2^{i}$ 分配给优先级级别 $i$ 。在加权循环下, 这意味着,每个 $\sum_{i} 2^{i}$ 调度决策中,优先级别 $i$ 队列中的事务占用时隙 $2^{i}$
3.Wait-Balancing Transaction Selection
解决read/write ratios和GC的干扰问题
一个事务所需要的资源正在被其他事务占用,那么当前事务阻塞
Wait-Balancing事务选择尝试在所有读和写事务中均匀分配此延迟时间,选择下列事务之一分派给FCC:
- 由优先级感知队列仲裁(第2阶段)确定的就绪读事务,该事务存储在dram中的read slot中
- 由优先级感知队列仲裁确定的就绪写入事务,该事务存储在dram中的write slot中
- 垃圾回收读取队列(GC-RDQ)前面的事务
- 垃圾回收写入队列(GC-WRQ)前端的事务
第一步,估计 Proportional Wait
将事务的PW定义为事务在调度器(Twait)中等待时间(从事务被调度程序接收一直到发送给FCC之间的时间)与 在内存中执行操作(TMemory)并将数据传输回前端(Ttransfer)所需时间的总和之比。
当读取事务的PW大于写入事务时,读取时隙中的事务优先于写入时隙中的事务
第二步,发送事务
如果读取事务优先,则会立即将其发送给FCC;如果写事务优先,调度程序还会考虑分派垃圾收集操作,因为写事务比读事务所需的时间要长得多。 因此,考虑垃圾回收操作可以与选定的写事务一起执行
“I want to say”
这篇论文主要是解决multi-queue中的unfairness问题,分析了导致其不公平的原因,四种干扰因素。对于每一种干扰因素提出了解决的办法,总体的思路是比较容易理解的。并且分三个阶段对其每一部分的干扰因素进行解决。不过看着还是有部分地方不是很理解。最近看的一些paper都是在NVMe SSD中解决Multi-Queue缺乏fairness影响性能问题。
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
good luck!