问题:
当写请求非常密集的时候,闪存内部的并行度并没有很好的利用
解决下述三方面引起并行冲突的问题:
-
冷热数据分离
-
垃圾回收:FS和FTL中的垃圾收集会发生冲突并破坏性能
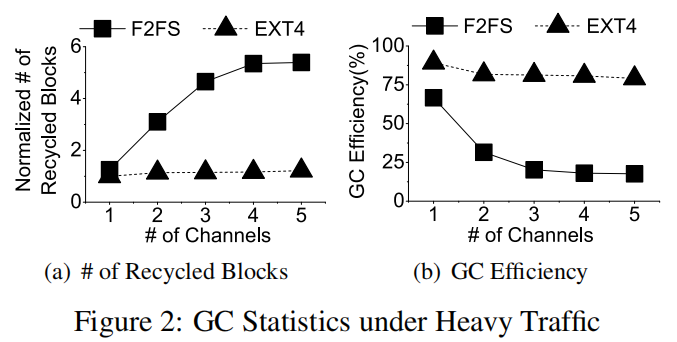
随着通道数的增加,F2FS的擦除闪存块数量增加,GC效率降低
当日志结构文件系统清理FS级别的一个段时,无效的闪存页实际上分散在多个闪存并行单元上。设备拥有的通道越多,无效页面就越多样化。这降低了FTL中的GC效率。同时,由于没有就地更新,FTL只有在收到来自日志结构文件系统的TRIM命令后才能获得页面的失效。正如我们在实验中观察到的,在FTL的擦除过程中,已经在文件系统中失效的大量页面被迁移到干净的闪存块上
-
一致性能
垃圾回收操作可能会引起延迟尖峰,通过I/O调度来解决
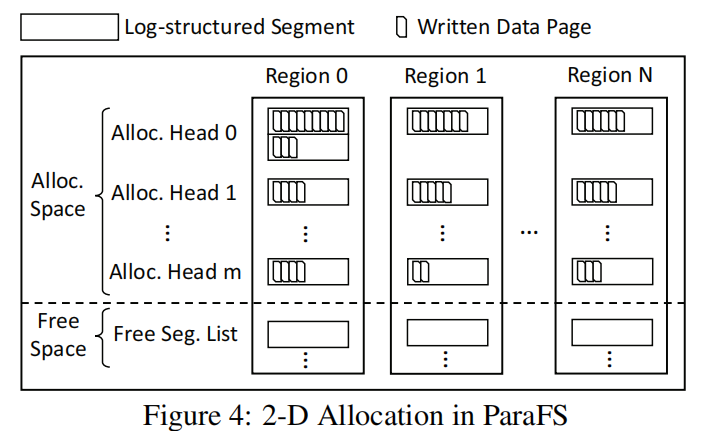
(1) 2-D Data Allocation
直观地说,文件系统数据组与闪存块对齐的最简单方法是在FTL中使用块粒度条带
块条带保持数据分组,同时将数据组并行化到块单元中的不同通道。
但是,块单元条带化无法充分利用内部并行性,因为一个组中的数据需要在同一个闪存块中顺序访问。
因此,我们提出了ParaFS中的二维分配,即利用小的分配单元充分利用信道级并行性,同时保持有效的数据分组。
Its size and address are aligned to the physical flash block.
将请求以页面为大小分配给不同的region,而且由于每个region和channel是一一对应的,在文件系统级别实现channel级的并行性
(2) 协调垃圾收集
FS和FTL级别的垃圾收集进程不匹配。(上层需要发送trim指令之后,底层才知道有些页面已经无效了)
ParaFS在两个级别上协调垃圾收集,并使用多个GC线程来利用内部并行性。
在FS级别中,当空闲空间降到阈值以下时,会触发前台GC;或者是文件系统空闲的时候触发后台GC。垃圾回收的时候以segment为单位。
前台GC采用 greedy algorithm快速回收片段,目的是最大限度地减少I/O线程的延迟。
后台GC采用的是cost-benefifit algorithm,选择victim segments不仅要根据无效页的数量,还要根据age。
如果页面迁移是由前台GC执行的,这些有效的页面将被条带化到在不同区域具有相似热度的分配器头上。
如果页面迁移是由后台GC执行的,则这些有效页面被认为是冷的,并条带到更冷的分配器头。
在将有效页写入设备后,victim segment将被标记为可擦除,并在检查点后被擦除
后台GC执行之后就退出;而前台GC在执行检查点后通过trim指令发送erase请求
在文件系统级别的segment和闪存级别的block是一一对应的,当文件系统层的GC之后,相应segment在迁移有效页之后,其所对应的底层block就可以被擦除,当S-FTL接收到上层的trim指令之后,victim segment对应的block直接擦除。擦除闪存块之后,SFTL通过回调函数通知ParaFS。
在此过程中,使得闪存级别不存在有效页的复制
由于ParaFS已经移动了有效的页面,S-FTL中的闪存GC可以直接擦除受害者块,而无需任何迁移。事实上,经过上述方法之后,将原本底层的GC迁移至了文件系统层,因此,底层几乎是不需要多余的空闲空间的。空闲空间仅用于坏块重映射和块映射表存储。
并且使用多个线程来优化前台GC
(3) 并行感知调度
解决GC引起的延迟尖峰
在文件系统级别调度读、写、擦除请求,包含请求发送阶段和请求调度阶段
在请求发送阶段,主要优化写请求,调度器为每个闪存通道维护一个请求队列。读取和擦除请求的目标闪存通道是固定的,而写入的目标通道由于延迟分配可以调整。
对于2-D allocation方式中,将一个写请求拆分成多个data pages,每个页选择一个目标region。而region和底层的channel一一对应,因此选择底层最不繁忙的channel进行写
并且给读写分配不同的权重(通过测量读写请求的相应延迟来获得权重),大致可以表示成如下形式:
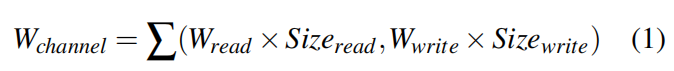
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
good luck!