ATC 2019,原文链接
LSM KV
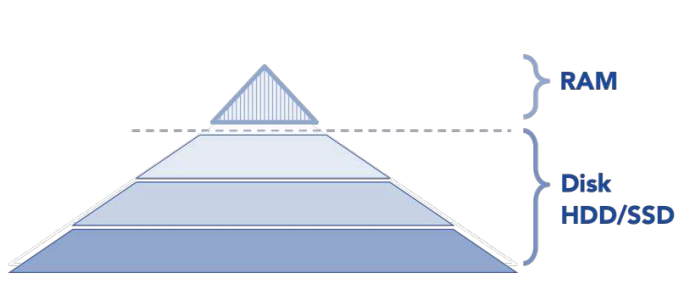
所谓的LSM(log structured-merge tree)是一种日志型结构的树。其中一部分在内存中(写缓存),其余部分在磁盘内。从图中可以看出,从上到下容量不断增加。因此,通过在内存中缓存写请求来提升写性能。
客户端操作:读、更新或者写;LSM内部的操作:flushing、compaction
内存中的文件称为memtable;硬盘中的文件称为SStable(sorted string table)
- 当一些写操作或者更新操作到达时,它们会被放到内存中,若内存满了则通过flushing操作刷到硬盘。因此已经刷回的文件并不会被修改,并且新的内容或者更新只是简单地生成了一个新的文件。那么随着越来越多的数据存到系统中,将会有更多的不可被修改的、顺序的文件,也即SStable。这些SStable代表了一小段时间内的按照顺序的写入或者更新。显然,这样的写特征也会导致数据的冗余。
- 为了将文件数量控制在一定的范围之内,系统会周期性的执行compaction操作,将上一层的文件合并到下一层的文件中。compaction时,需要将文件先读到内存,执行完后在写回。并且,在此过程中将一些重复的更新和数据的冗余删除掉。
- 当一个读操作请求时,系统首先检查内存数据(memtable),如果没有找到这个key,就会逆序的一个一个检查sstable文件,并且由于每个文件都是顺序的,因此读的效率比较高。但是随着SStable数量的增加,读操作会变得越来越慢。那么可以使用LRU将一些数据缓存在内存中
问题及原因
-
L0满了以致于不能进行flushing,导致在内存写满后不能处理新的请求
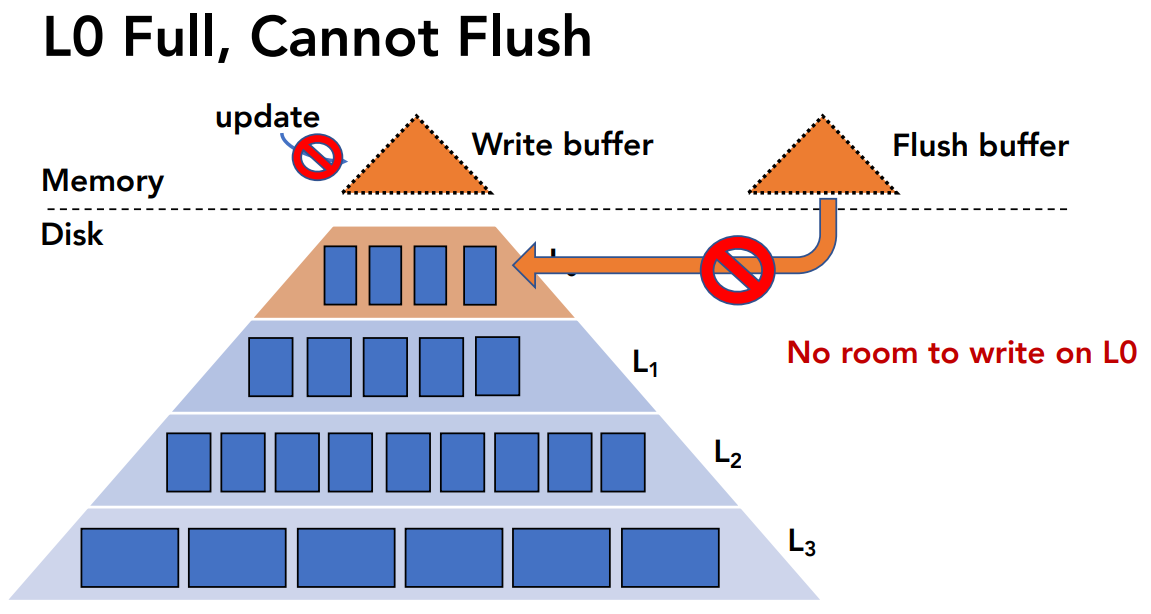
原因:

为什么会有那么多的high-level compaction同时发生呢?
每次处理写请求都是创建新的文件,原来旧的文件不做处理。只有当累积的新文件达到阈值时,所有这些新文件才会合并到旧文件中。最糟糕的情况是,所有存储的数据都包含在一轮compaction中,导致了巨大的尾延迟。 -
flushing速度缓慢导致内存耗尽了,flushing还没完成,这时候内存中没有剩余空间,不能处理新的请求
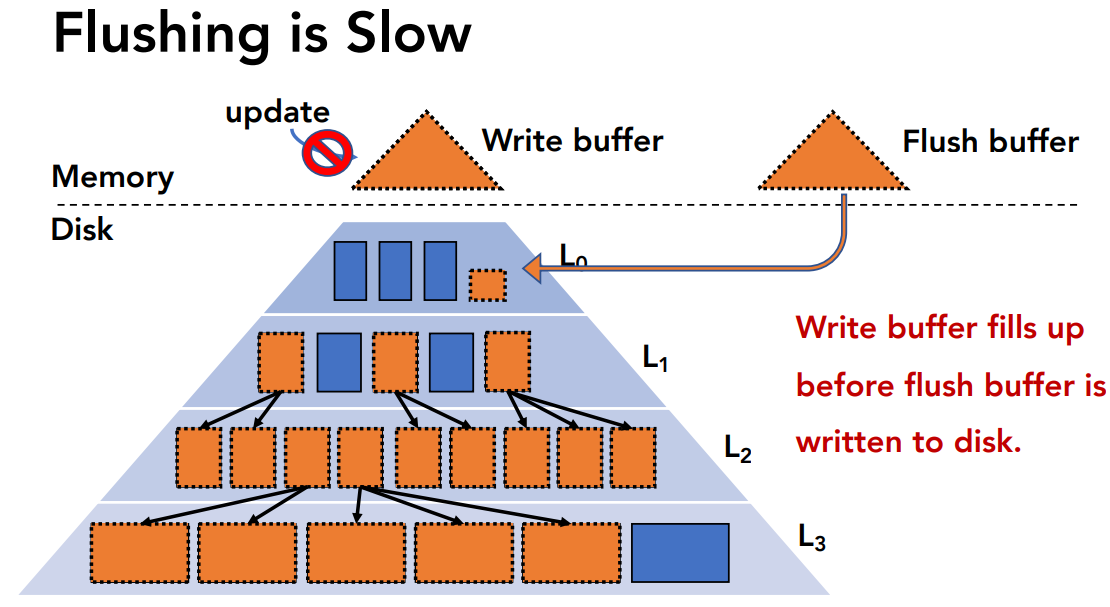
原因:

先前的解决办法
- 限制compaction的比率
这种方式简单地协调了内外部操作,但是从长远来看,并不好,会导致一些并行compaction的累积
- 延迟compaction
Selective/Delayed Compaction (TRIAD [USENIX ATC ’17], PebblesDB [SOSP ‘17]).
这种方式并没有避免干扰,最终还是要执行延迟的compaction操作
SILK
- Make sure L0 is never full.
- Ensure sufficient I/O for flush/compactions on low levels.
- Higher level compactions should not fall behind too much.
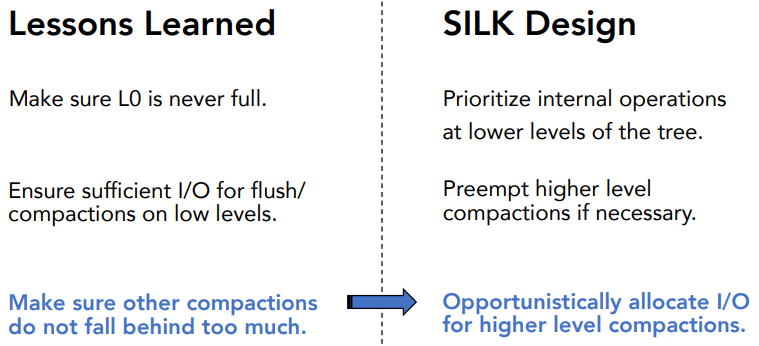
因此,SILK提出了一种I/O调度算法,合理使用Prioritize和 Preempt
专门给flushing和L0到L1的compaction配置I/O带宽,因为这两者直接影响客户端的延迟
动态的调整客户端和内部操作的带宽
低层操作的优先级别更高,并且可以抢占高层操作
“I want to say”
本文发现问题的思路非常巧妙,让人读起来感觉说得合情合理。并且对LSM KV存储的解读也非常到位。提出I/O调度方法很好的提升了性能。当然也是存在一定的问题的,还有待考虑。现在很多文章也讲到LSM KV存储,当然,这涉及到数据库的知识点,还没有深挖。
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
good luck!