在传统的TLC SSD中,不区分page type,因此由于不同的子请求分到的page-types不一样,那么产生的延迟也就不同,而对于一个用户请求来说,需要等到所有的子请求都完成返回之后才算整个请求结束,这就造成写效率非常低。根据存在的这个问题本文提出PA-SSD,将单个用户写请求所分的子请求使用相同的page type进行分配。具体为:对于每个用户请求分配第一个子请求时,根据本文提出的7种页面类型选择策略来确定page-types,然后,接下来对于同一个请求中的子请求,均使用相同的页面类型。原文链接
我们知道,从SLC到MLC再到TLC,以及之后出现的QLC,在储存单元上做了改变,从原先一个单元上存放一个bit,到后来存放四个bit,那么我们今天要讲的主人公式TLC,它的内部存放的是3个bits
根据存放位置不同分为LSB (Least Significant Bit),CSB (Central Significant Bit) 和 MSB (Most Significant Bit),其中,LSB(fast),CSB(medium),MSB(slow)
分为两个问题:
- 如何确定每个写请求的页类型
- 对于确定的页类型,如何分配,这里涉及到block的分配策略和确定好block之后page的分配策略
先来看一张SSD框架图,虽然之前也介绍过很多遍啦:

PA-SSD
传统SSD的写请求工作流程:
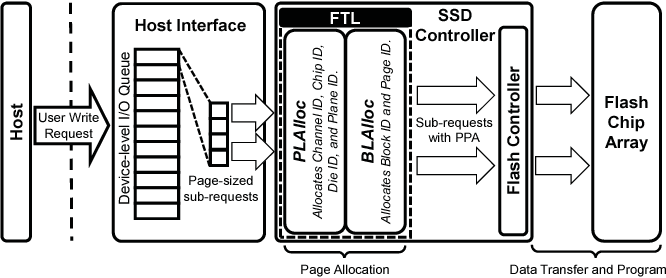
这里需要指出的是,在PLAlloc中分配了channel ID,chip ID,die ID,plane ID,我们知道这四级都是可并行的。BLAlloc中分配了block ID、page ID,确定访问闪存单元的具体某个page
PA-SSD中写请求的工作流程:
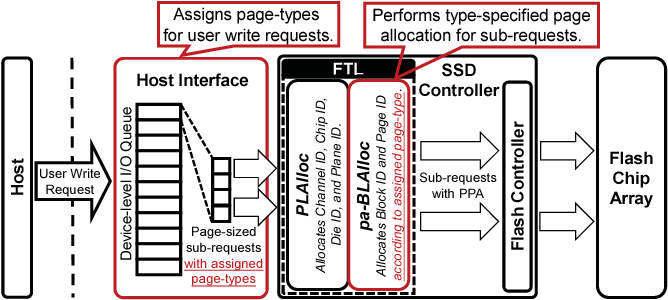
上图描述了写入请求执行的整个流程,由Host Interface分配一个用户写请求的page-types,当然它的所有子请求均是同一个page-types了。 原先的BLAlloc primitive由pa-BLAlloc代替,并且根据分配好的page-types来给子请求分配页
很清楚地分为两个步骤(红色方框):
1.PA-SSD中的主机接口根据特定的页面类型指定方案为每个请求预先分配一种页面类型
2.在FTL的pa-BLAlloc对于页大小的子请求,分配block id 和 page id 来指定type-speccified page
1.Page-type Specifying Schemes确定页类型(7种分配方案)
1.Uniformly Specification (US)(均分)
对于用户请求,采用RR方式仲裁,所以对于对于每个请求来说选哪种类型的page ,都是等可能的。LSB、CSB、MSB均是1/3,这将导致LSB dominated writes, CSB dominated writes, and MSB dominated writes统一分布
自然这种方法的话不会随着n的增大而使得某一种主导型的写占比增多
2.Host-Guided Specification (HGS)(由host决定)
对于一个在NVMe中的command,host可以通过设定two-bits属性表示“Access Latency”来获知响应时间的要求。然后根据写请求的响应时间要求来决定选用哪一种的page type
其中,LSB、CSB、MSB的延迟分别为short、medium、long
在此方案中,如果主机没有申明响应延迟,那么就采用其他方案 ,比如US
3.LSB-First Specification (LFS)
首先将LSB分配给用户写请求,以保证贪心思想,最大程度地提高写性能
缺点:然而,当使用此方法的时候,LSB会很快被用完,留下CSB和MSB
此方法作为写密集型突发的时候来提高写性能
4.Size-Based Specification (SBS)
在大多数情况下,比较短的用户写请求所需要的响应延迟也就相对比较低,那么给small-sized(小于8KB)请求分配LSB对于large-sized请求使用其他方案,例如US
5.Queue-Depth-based Specification (QDS)
在主机接口端存有I/O queue,队列的长度可体现出I/O的紧密程度
在很忙的情况下,当一个队列很长的时候,请求的响应时间主要由他们的响应时间来决定
通过缩短每个用户写入请求的程序延迟,可以大大缩短等待时间(比如说前面的请求响应很快,那么排在后面的请求也能很快轮到,进行处理),从而提高写入和读取性能
当设备级的I/O队列长度超过阈值时(比如十个请求),那么将LSB分配给队列中所有的写请求
当队列长度比阈值要短时,采用其他方案,比如US、UBS。QDS可以被看做是dynamic-LFS方案,根据队列深度动态的启用LBS和停用LBS,事实上,如果将阈值设置为0,那么就成了LBS方案
6.Write-Buffer-based Specification (WBS)
当写缓冲区满的时候,使用LSB类型的页进行分配。
WBS方案只能感知写入强度,通过在读密集型期间加速写入请求来提高效率
此外,写入缓冲区可能被延迟不敏感的large-sized写请求填充,导致使用WBS时浪费LSB页
事实上,当写缓冲区很小的时候,WBS实际上成为了LBS方案
7.Utilization-Based Specification (UBS)
由于不平衡的使用将导致GC效率低下
根据三种页面类型各自剩余的页面数目,那么可以有效的平衡他们的使用
使用UBS,PA-SSD根据pl、pc和pm三种概率确定写入请求的页类型,即分别使用LSB、CSB和MSB页面类型分配
设置pl:pc:pm=#LSB:#CSB:#MSB
#LSB,#CSB,#MSB表示的是在运行期间SSD内部的三种类型的page数目
此方案由于在GC的时候尽量保持三种类型的页面数量相同,不至于使得LSB类型的page消耗殆尽
paper中的实验部分结果是QDS+UBS结合的方式写性能可以在更长的时间内保持良好
2.Type-Specified Page Allocation
在传统的SSD设计当中,确定了某个Plane之后,只有一个活动块,且每个活动块中只有一个候选页,来服务和页大小一样的子请求。TLC块中的页面应该按照它们的ID顺序编程,如下图:
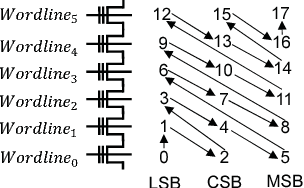
考虑到前四级的并行性,那么选择在plane内部进行page-types的选择。在上述分配流程中我们可以看出,同一层的wordline能够保证LSB先分配而MSB最后分配,并且一个已经使用的wordline只会被相邻的wordline影响。
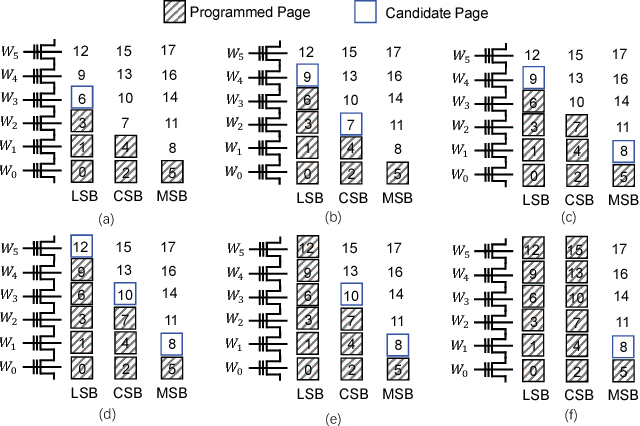
Candidate pages within an active block in PA-SSD. In (a), only the next LSB page is a candidate page; in (b), both the next LSB page and CSB page are candidate pages; in ©, both the next LSB page andMSB page are candidate pages; in (d), all of the next LSB page, CSB page, andMSB page are candidate pages; in (e), the LSB pages are used up, leaving only CSB and MSB pages for serving subsequent sub-requests; in (f), both the LSB and CSB pages are used up, leaving only the slowest MSB pages for serving subsequent sub-requests.
- LSB、CSB 、MSB pages在被编程的时候是根据他们ID的顺序
- CSB只有当相邻的LSB分配完了才能作为候选而被使用
- MSB只有当相邻的CSB分配完了才能作为候选而被使用
采用上述方法使得在一个plane中可达三个块,在一个块中可达三种候选页
�I want to say�
近段时间基本每天都看paper,想想也看了挺多了,突然感觉好像在读论文方面是快很多,越来越少使用Google 翻译了,一长句话也能多扫几眼猜出意思——阅读paper的体会
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
good luck!