这一篇是前段时间遗留下来没有做完整讲述的paper,今天写了一个详细的博文供大家学习参考!
讲述的多流技术不同于以往要么是应用级别的分流,也不是块级别的分流,而是文件系统的分流技术。
FStream: Managing Flash Streams in the File System
PPT
在看本文前可以先看我之前的博文Multi-Stream SSD,了解一下Multi-Stream SSD是怎么回事!
导语
SSD的性能和寿命不仅取决于所承受的
工作负载,还取决于内部媒体碎片(数据放置的位置),内部媒体碎片的产生不仅取决于写入模式,还取决于数据如何已经放置在SSD中。随着时间的推移,SSD内部的碎片越来越多,GC操作变得十分频繁。
最近也有其他的文章提到的Streams,方法是主机来控制数据放置的位置(通过Stream ID的方式),这种方法有效减少了媒体碎片的产生。
而本文的方法——FStream,利用了这个Stream技术实现的文件系统方法。FStream在文件系统级别提取流,并避免将复杂的应用程序级数据映射到流。
介绍
随着SSD的发展,正快速的取代HDD在企业级数据中心的使用。SSD借助内部软件(通常称为闪存转换层(FTL))来维护传统的logical block device。
FTL允许SSD代替HDD后,无需对OS的块设备接口进行复杂的修改。
write amplification factor(WAF): 实际的写次数和用户I/O写次数之比(注意这里用户I/O之所以多是因为GC操纵所带来的额外的写操作,被擦除块中如果有Ivalid page,就需要写到另外空闲区域)
为了解决WAF问题和磨损均衡问题,已经做了大量的工作了。关注点在于如何利用多流SSD技术。原则上,如果主机系统完美地将具有相同生存期的数据映射到相同的流,SSD的写放大值为1,完全消除了媒体分裂的问题。
先前的研究策略有两种:
- 第一种策略是根据对这些数据的预期生存期的理解,将应用程序数据映射到不同的流。比如日志文件分为单独的一个流,案例研究表明,这种策略对于诸如Cassandra和RocksDB这样的NoSQL数据库非常有效。不幸的是,这种应用程序级定制策略要求系统设计人员很好地理解目标应用程序的内部工作,对设计人员是一个挑战
- 另一种策略旨在“自动化”将写I/O操作映射到没有应用程序更改的SSD流的过程。例如,最近提出的AutoStream方案根据来自过去LBA访问模式的估计生存期为每个写入请求分配一个流。然而,该方案在复杂的工作负载情况下,特别是在工作负载动态变化的情况下,没有得到很好的证明。
上面概述的策略是两个极端:application level customization(应用层定制) vs. block level full automation(块级完全自动化)
本文的工作采取了另外一个措施,在文件系统层分离流,我们的方法的动机是观察到文件系统元数据metadata和日志数据journal data是短暂的,是将用户数据分离的良好目标。
本文的工作在Linux EXT4和XFS文件系统中实现了FStream
WAF
GC操作会带来额外的写操作,测量GC操作的唯一指标是write amplification factor(WAF),它被描述为在闪存上执行的写操作与从主机系统请求的写操作的比率。
WAF = Amount of writes committed to flash/Amount of writes that arrived from the host
随着ssd老化,WAF可能会更频繁地飙升
FStream
与文件系统相比,应用程序可以更好地了解写入数据的生存期和更新频率。但是,应用程序不知道文件系统metadata的生存期和更新频率。与应用程序的数据相比,文件系统元数据通常具有不同的更新频率,并且常常受到特定文件系统的磁盘上布局和写入策略的影响。通常,文件系统保持数据和metadata逻辑分离,但它们在SSD上可能不会保持“物理”分离。在执行文件操作时,元数据写入可能与同一NAND块中的数据写入混合,或者一种类型的元数据可能与另一类型的元数据混合。具有流分离能力的文件系统可以减少应用程序的数据和文件系统元数据的混合,并提高waf和性能。
因此,本文的方法是这样的:
- 在文件系统级别进行流分配
metadata、journal、user data进行分离,作为单独流的形式- 在现有的Linux文件系统EXT4和XFS实现FStream
EXT4
ext4文件系统将磁盘区域划分为多个称为“block groups”的大小相等的区域,如下图所示
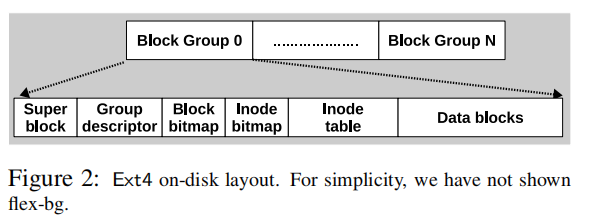
每个block group都包含数据和相关的metadata,以减少对HDD的寻找。
每个文件都有其对应的inode,默认大小是256bytes。这些inode存储在inode表中。inode bitmap和block bitmap分别用于inode和data blocks是否分配的标记
Group descriptor包含了块组中的其他元数据区域(inode table、block bitmap、inode bitmap)的位置信息
文件系统一致性是通过journal中的write-ahead logging来实现的。日志是一个特殊的文件,其块驻留在用户数据区域,在文件系统格式时预先分配。Ext4有三种日志模式:data-writeback(metadata journaling),data-orderd(metadata journaling + write data before metadata),data-journal(data journaling)。默认模式是data-orderd
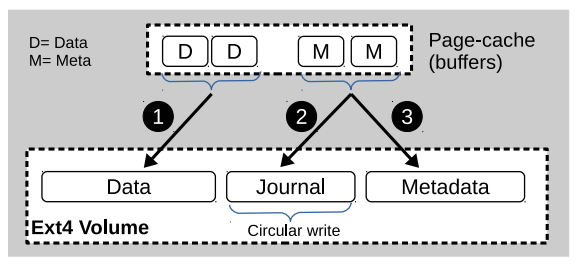
上图是journal in ordered mode。Ext4按顺序写数据和journal,Metadata blocks在持久化到journal后会被写入它们的实际归属位置
在事务期间,ext4更新内存缓冲区中的元数据,并通知jbd2线程提交事务。 jbd2维护一个计时器(默认为5秒),在到期时它将修改后的元数据写入日志区域,除了与事务相关的簿记数据。 一旦更改持久,该事务将被视为已提交。 然后,通过回写线程将内存中的元数据更改刷新到其原始位置,这称为检查点
EXT4Stream

Experiment

Filebench results
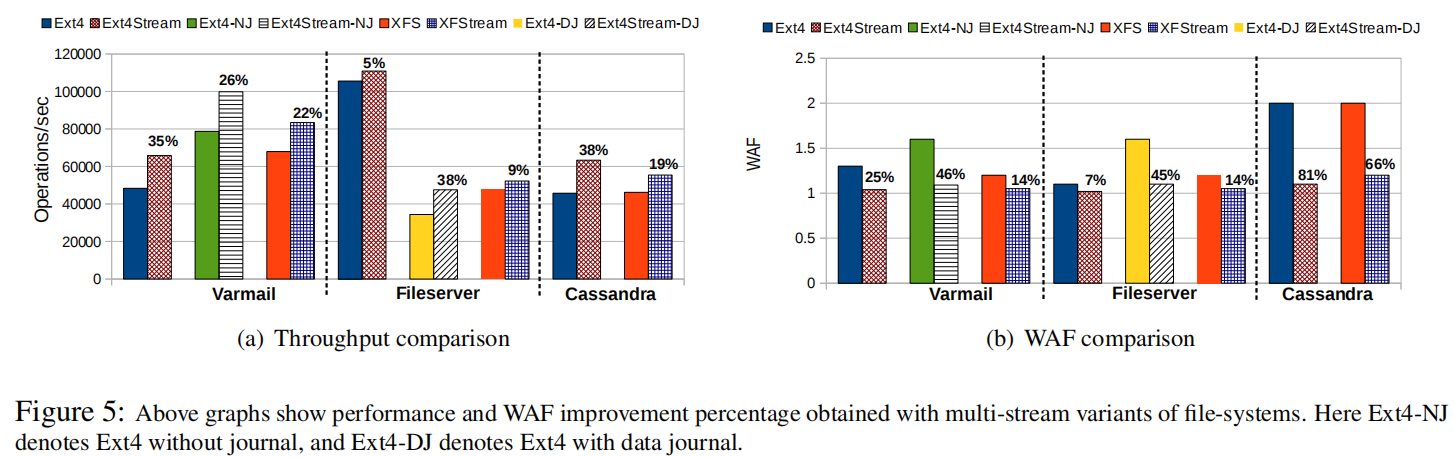
将元数据或日志分成不同流的好处取决于元数据写入流量的大小和各种I/O类型之间的混合程度。如图5(a)所示,对于varmail,Ext4Stream显示35%的性能提升和25%的WAF减少比baseline ext4。与xfs相比,XFStream显示varmail的性能提升22%,WAF降低14%。Ext4Stream和XFStream都显示出对varmail的更多启用,而不是文件服务器,因为varmail比文件服务器更加元数据密集,如表3所示
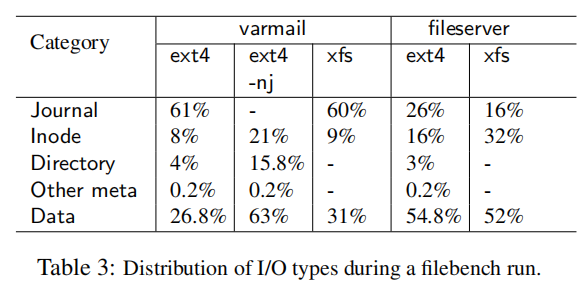
- 一个重要的观察是在文件服务器中,减少元数据写入对于性能而言比减少日志写入更重要。与ext4相比,xfs为文件服务器生成16%的inode写入和10%的日志写入。虽然元数据和日志写入的总和相似,但xfs的性能不到ext4的性能的一半。原因是元数据写入是随机访问,而日志写入是顺序访问。顺序写入对于FTL的GC效率更好,因此对性能和寿命有益。
- 另一个重要的观察结果来自表3中的ext4文件服务器写分配,其中显示16%的inode写入,但只有0.2%的other-meta也包括inode-bitmap。这是因为jbd2优化。如果事务修改了已经很脏的元缓冲区,jbd2会通过重置其脏定时器来延迟其回写,这就是为什么inode/block位图缓冲区写入仍然保持低,尽管有大量的block/inode分配。
如图5(b)所示,在文件服务器测试期间,ext4 WAF保持接近1。但是,当ext4使用data = journal模式(由ext4-DJ显示)时,由于journal和应用程序数据之间的连续混合,WAF飙升至1.5以上。 Ext4Stream-DJ消除了这种混合,并将WAF降低到接近1。
Cassandra results
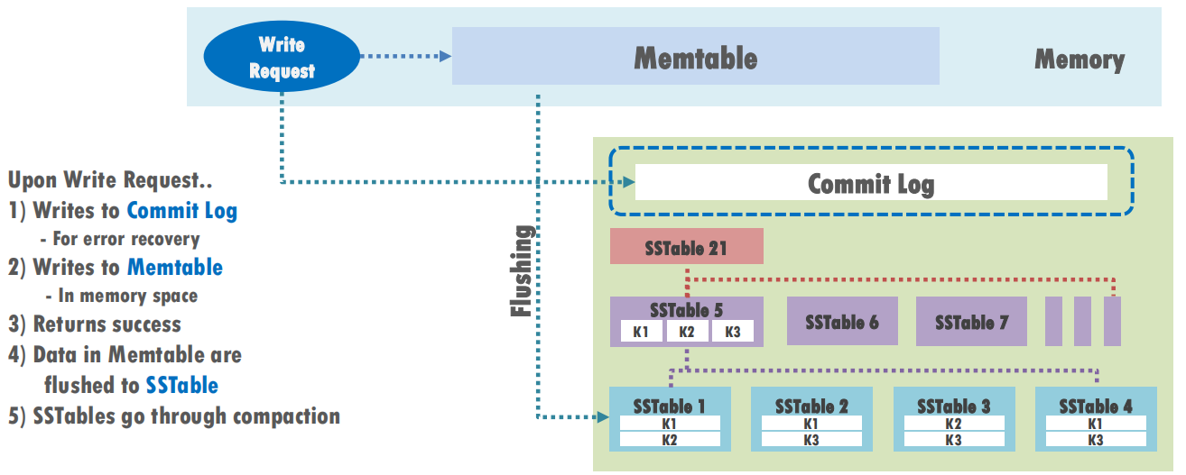
- Cassandra工作负载属于数据密集型
- 数据库更改首先进入内存结构,称为“memtable”,并写入磁盘上的commitlog文件。
- commitlog实现Cassandra数据库的一致性,就像文件系统日志对ext4和xfs一样。它写得比文件系统日志要频繁得多。
- 通过将提交commitlog与database分离,由文件系统通过检测commitlog files的文件名来完成,我们观察到吞吐量提高了38%,WAF降低了81%。
- 使用fname stream选项,名称以commitlog开头的文件将流入单个流。 即使多个Cassandra实例在单个SSD上运行,commitlog文件也只会写入fname stream分配的流。
总结一哈
本文提出了一种在文件系统层中应用多流技术的方法,以解决SSD老化问题和GC开销问题。之前关于多流技术要么是application level customization,要么是 block level full automation。本文提出的方法不同于上述两类方法,即在文件系统层分流。
- 重点研究了文件系统生成的数据的属性,例如日志和元数据,因为它们存在时间短,因此适合于流分离。
- 实现了这些文件系统生成的数据的自动分离,不需要用户干预。
- 不仅提供了元数据和日志的全自动分离,还建议将应用程序对不同流使用的redo/undo日志分离。
- 流分离方案FStream实现了物理数据分离,帮助FTL减少GC开销,从而提高SSD的性能和寿命。
- 将FStream应用于ext 4和XFS,并为各种模拟数据中心中的真实服务器的工作负载取得了令人鼓舞的结果。
- 实验结果表明,我们的方案将filebench性能提高了5%,并使WAF降低了7%~46%。对于Cassandra工作负载,性能提高了38%,WAF提高了81%。
�I Want To Say�
这一块知识之前了解的不多,总体看下来还是很多疑惑;对于文件系统的内容之后学习过程中遇到的问题也会写写博客的。最近事情比较多,可能之前关于NVMe的博客计划进度会慢一些,尽快会补上!
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
good luck!