4月美国举办的ASPLOS19’上一篇最新的paper,来自Myoungsoo Jung大佬团队
问题引入
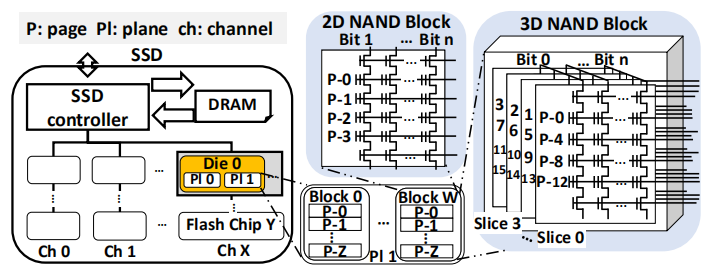
1)3D NAND相比于2D NAND具有更高的density,因此同等容量下,3D NAND的chips数量相对就少,降低了chip-level parallelism。这会导致在相同的时间内被处理的请求数量减少,从而导致整个性能的下降。
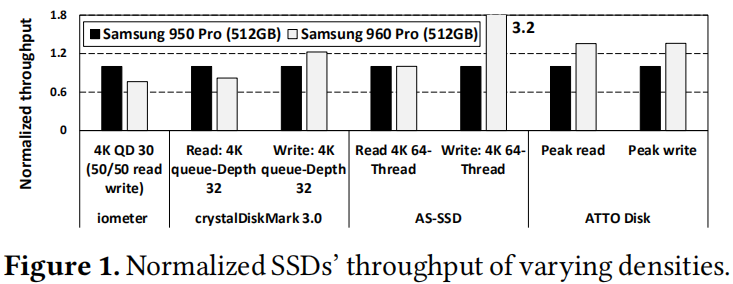
从图中可以看出,对于read-intensive 的应用不适合在3D NAND芯片上使用,而对于写操作,由于buffer的存在,因此影响并没有那么严重
2)再者,数据在闪存中的分布是比较分散的,也就是说一个read operation(16KB),而大多数的read request是4KB或者8KB。这可能会导致一个请求占用多个chips资源
问题分析
NAND Read Operation
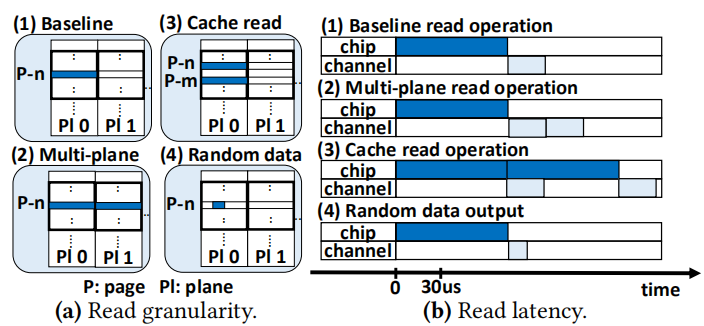
读延迟包含两个部分,一个是数据读取的时间(从cell读到chip internal buffer),一个是通道传输延迟(chip internal buffer传到SSD控制器的ECC纠错部件或者DRAM buffer)
Read Operation有以下四种:
1)Baseline:在单个plane读一个页
2)Multi-plane:相较于baseline,提升了chip的吞吐量
3)Cache read:内部有两个buffer,一个用来cell data reading,一个用来data transfer,因此两个操作可以并行执行
4)Random data:只读取所需要的部分数据,降低了数据传输的时间
虽然3D NAND 支持上述读操作,但是由于芯片密度的增加,数据读取的延迟依然会很高,这是因为密度增加所导致cell sensing time更高了,而数据的传输延迟可以通过时钟来控制,因此主要问题还是在于读取延迟。实际上,最高读取延迟可以上升至90微妙
负载测试结果分析
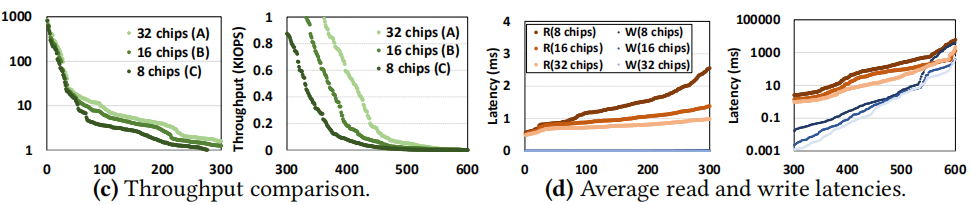
x轴表示600个负载,按照纵坐标的大小进行了排序,可以看到随着芯片数量的减少,导致chip-level并行度差,吞吐量变差,延迟变高。
文中提到DRAM对读请求的改进是很有限的,主要因为超过80% 的数据在400个负载中只读取了一次,这种时间局部性这么差主要原因是频繁读取的数据被缓存在上层。
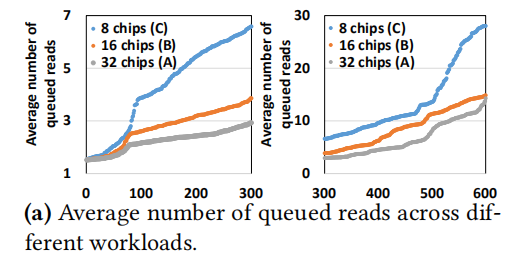
上图显示,芯片数量少,导致队列中排队请求多,队列长。
这是由于芯片的减少导致芯片并行度下降了,那么想着可以通过某种方式提升芯片内部的并行度~
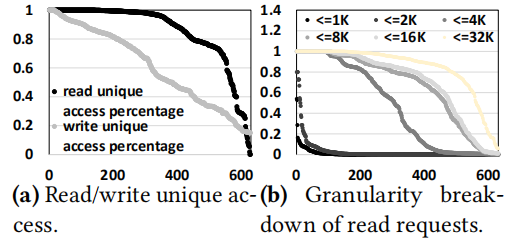
注意,当前的3D NAND页面至少有16 KB,这是读取操作的最小单位(粒度)。只有很少的工作负载被1K或2K的读取请求所支配。大量的工作负载主要是4K和8K的读取请求。具体来说,300和480个工作负载主要包含小于4K和8K的读取请求。
当然,4K和8K的请求可以通过某种方式按照16KB的请求来操作。
策略
针对上述问题和分析,本文提出了SOML(Single-Operation-Multiple-Location),实现block级别的并行读partial page(部分页)。并且提出了一种的调度算法,实现了将多个小粒度的读请求合并成一个大请求来操作。
在2D NAND中,增大读操作的粒度可以提升cell density,但是在3D NAND中,反而需要降低读操作的粒度;从上述分析,我们知道了两个关键点:1)3D NAND chip parallelism下降了;2)Read 请求的大小往往比baseline中的page要小
因此也就产生了上述读取部分页的操作,并且为了弥补chip间并行度的下降,提升了chip内部的并行性,实现不同block间的部分页并行读;例如读一个在block0中的8kb大小的page1和在block m中的page 0
为了更好的改进性能,本文还实现了算法来发现和combine多个小的读请求,作为一个SOML 读操作来实现
创新点:1) partial-page read operation 2)simultaneous multiple partial-read operations across blocks
partial-page read operation
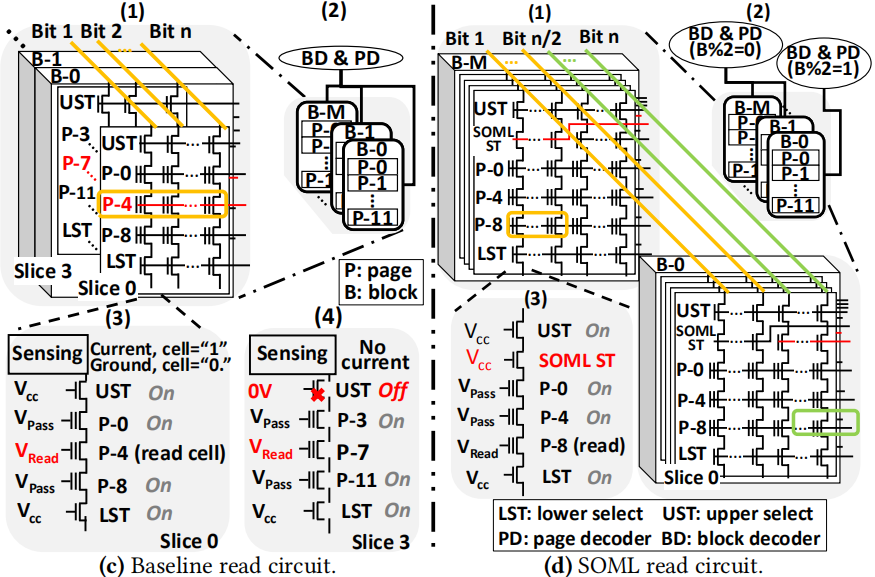
BD(block decoder)& PD(page decoder)会选中一个block,并且读取部分页。因此只有一个block才会接收到PD的控制信号,PD通过layer signal和slice signal对所读取的页进行索引。请注意,其他层和片信号将被设置为适当的值,以指示“off”,以便 读取相应的页面
例如(c-3,c-4)中,需要读取page 4 和 7,那么第一层中的page-0和第三层中的page-8设置成Vpass,第二层中所要读取的page-4设置成Vread,这样可以确保只有存储在page-4中的电子才会通过bit-lines 外流到sensing circuits
在读操作情况下,LST (lower select transistor)被设置为Vcc,UST(upper select transistor)作为切片信号。更具体地说,所选片的UST设置为Vcc,而同一块中其他片的UST设置为0V。因此,虽然其他切片接收相同的layer signals,但数据不会外流,抑制来自其他slices的读取
为了实现部分页的读取,在UST和第一个cell layer之间插入新的transistor,SOML ST。d-1中,因此在上述基础之上,可以通过不同的控制信号(红线)选择前半页/后半页。当然可以加入更多的SOML ST来支持更细粒度的读取
simultaneous multiple partial-read operations across blocks
要实现同时读取,必须修改BD和PD,这样才能访问来自不同块的不同页面。PD被复制成索引两个不同的半页读取操作,而BD被分成两个较小的BD,其中每个都可以索引一半的块
需要注意的是,并行读取是在不同的block之间进行的,同一个block内并行读取是不可行的
调度算法
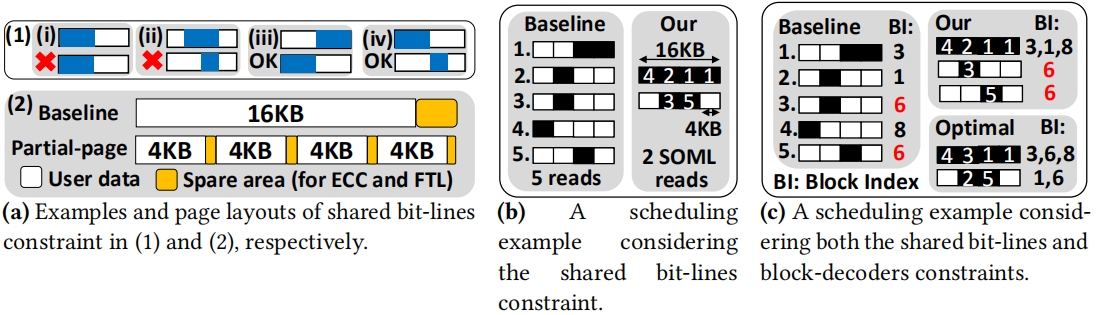
想法很简单,就是将不同block中的交错的页作为一次SOML 读操作执行。
注意两点即可,并行操作的块是不同的块,并行块中的页需要错开。(具体可以看paper-5.1)
“I want to say”
这篇paper从硬件上对现在3D NAND中存在的并行度差进行改进,方法非常好而且很灵活,对读取页粒度的控制可以通过增加SOML ST的个数来控制,但是毕竟是从硬件上修改,需要开销,并且不能实时适应系统状态的改变。适应场景也比较受限。
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
good luck!