本文提出的idea主要用来解决SSD内部不规则行为所导致的响应延迟不一致而影响QoS问题,此问题的存在导致不能很好的展现SSD的高性能、低延迟、低开销优势
导语
现代的SSD不仅仅是一个快速存储设备,而是一个高度复杂的计算机系统,这个复杂的系统有一个嵌入式处理器和多个硬件单元组成,例如,flash cells、channel。嵌入式处理器执行复杂程序以实现非易失性单元的可编程性(例如,读取,写入,擦除操作),并且还改善了设备的整体性能和耐久性(例如,垃圾收集,缓冲,负载平衡)
为了解决上述问题,提出一种精准预测未来访问的延迟方法,然而
- 用户不可见,缺乏公开的信息
- 操作复杂
在本文中,提出了SSDcheck,一种新颖的SSD性能模型,用于准确预测SSD上未来访问的延迟
- 首先,通过重构SSD和性能测试实验,确定影响SSD延迟的两大关键因素——write buffer和GC,然后,SSDCheck基于这两个特性构造了一个通用的性能模型
- 其次,在启动应用之前,SSDcheck运行诊断代码片段,以提取特定设备的静态特征参数(例如,内部卷的存在,write buffer的大小、buffer flush算法),使用此信息为目标设备配置通用ssd性能模型
在运行时,SSDCheck监视传入的I/O请求,以动态管理性能模型。该模型基于预测的不规则行为的发生,有效地预测了请求的延迟。SSDCHECK还可以校准其模型参数,以适应模型以处理未建模的特征
为了证明SSDcheck的有效性,本文除了对实际SSD进行测试,还评估了两个用例:一个新的卷管理器和一个利用延迟预测的新I/O调度器。
基础知识
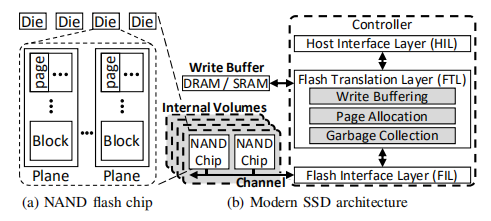
现代SSD的通用架构:
闪存操作延迟:read(大约60微秒)、write(大约1000微秒)、erase(大约3500微秒)
NAND型闪存芯片不能就地更新,因此,多次写在相同的page上时,必须要先擦除再写(erase-before-write)
图b中,显示了现代SSD的典型架构:controller、write buffer、NAND flash chips
controller由HIL、FTL、FIL三部分,其中
HIL接收I/O请求发送给FTL,FTL将它们翻译成一系列的NAND操作,并将这些操作发送给FIL,FIL将这些操作通过channel发送给独立工作的chips,通过管理这些channels,一个SSD能实现通道间/内的并行性、
在这些架构中,最关键的时FTL,其有三个核心函数:write buffering、page allocation、 garbage collection
1.Write buffer
为了隐藏写操作的长延时问题,FTL暂时将这些写数据存到write buffer(WB),并把它们排到后台的闪存芯片上,但是如果buffer达到一定的阈值时,必须将buffer中的数据立即flush到flash chips。从上面,我们已经知道了,flush操作大约需要3500微秒,在这个过程中,对性能要求比较高的read操作将会延迟
我认为的read对延迟比较严格的理解是read操作只需要大概60微秒的时间,那么3500微秒在read对比看来自然是个天大的数字,因此可以说,read延迟短,对延迟要求严格,flush操作对紧接着后面的read操作将会带来很大的影响
2.Page allocation(应当是有一个mapping table来存LBA与分配的PBA映射关系)
将LBA映射到flash chips上相应的PBA,从空闲的page pool中选择一个新的page作为当前write数据的page,先前对应的PBA置为Invalid
为了减少页面分配开销,一些SSD采用多个用户未暴露的分配卷,它们独立地控制每卷页面分配单元,一组通道中的闪存芯片和写缓冲区
FTL通过检查请求LBA的特定地址位来确定目标卷,并且每个LBA仅映射到卷中的闪存芯片集
3.Garbage collection
- 选择victim块(根据victim 选择算法)
- 在这个选择的victim中,将valid page merge到free page上
- 擦除victim block
这里需要注意的是,merge操作中的valid page只能移动到GC卷指定的预定义chips上
当然,在FTL上,也可以通过执行其他操作来改善性能,例如,power management,read-ahead,SLC caching等等或者可靠性,例如,wear-leveling,ECC等等,但是以上三个是最关键的性能特征
Irregular Behaviors
来源
intra-SSD irregularity 主要是由于内部组件以及它们之间的交互所带来的影响,例如,
- 即使write buffer可以有效隐藏写延迟,但是其不规则的flush可能会导致read请求的延迟
- 即使分配多个卷在性能上是有效的,一些LBA访问模式可能导致不规则的卷激活
- 不规则的GC调用及其高度变化的开销
inter-SSD irregularity主要来源于设备特定的设计和优化,例如,
- 供应商可能希望通过实现一个大的写缓冲区和许多分配卷来实现快速的ssd,而另一个供应商可能希望通过均衡磨损的方法来改善ssd的生存期, 但GC比较慢
因此,这种特定于设备的设计和优化会导致不同SSD之间的高度不规则行为。
Benefits of Predicting
准确地预测下一个请求的延迟对于减少SSD中的性能不规范起着至关重要的作用,例如,准确预测NL(或HL)请求,可以在HL请求之前调度NL请求,从而提高吞吐量和QoS
要精确的预测 NL 请求,将NL请求放在HL请求之前处理,但若预测错误,那么会导致NL 请求误认为HL请求而延后,从而造成性能下降,这里的NL可以是read请求,而HL可以是flush,之后也会举例子
Model
下图显示了SSDcheck是如何为SSD创建一个性能模型的,在运行期间,SSDcheck动态地管理性能模型来预测将来的延迟:
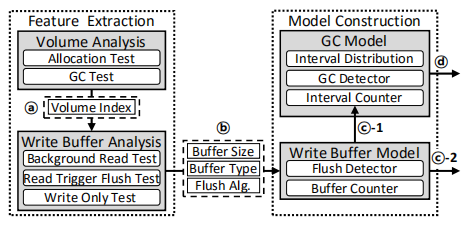
过程:
- SSDcheck首先提取内部卷特征(如a)
- 使用信息来测试提取具体设备的写缓冲区参数(如b),并且发送这些信息给model construction part
- model construction会动态构建write buffer model 和GC model
write buffer model
buffer model动态地管理buffer counter和flush detector,当一个写请求到达write buffer model时,buffer counter加一,当buffer counter的值达到buffer size时,那么就需要进行flush操作,启动flush detector进行flush,并重置buffer counter
同时,buffer detector把flush事件通知给GC(c-1,GC于是乎知道了有这么一个事件过来了,他就得做好准备,查看是否需要垃圾回收,已准备足够的空间给flush操作使用),也将此事件发布到性能模型的外部(c-2)。如果write buffer使用了read-trigger flush 算法,那么flush detector
GC model
GC model管理interval counter和interval distribution,以实现基于历史的预测,从而将缓冲区刷新的历史与GC事件关联起来
简单来说,就是通过检查间隔写请求分布,GC检查器确定后续缓冲区刷新是否会触发GC进程
如果GC detector确定当前的写请求会影响GC,那么将此GC事件暴露到性能模型外部(如d)
interval counter记录buffer flush次数,决定了GC victim选择算法和有效页的分布情况
SSDcheck动态管理框架:
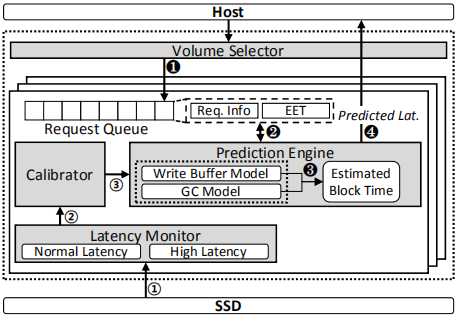
host发送查询给framework来检查一个不规则事件的产生,framework返回一个预测延迟
主要分为Volume selector、Prediction engine、Latency monitor、calibrator
Volume selector
host发送一个请求给framework来检查这个请求是否会延迟——>然后这个请求通过Volume Select,转发给相应的内部响应卷(通过LBA中的volume indices)——>framework将请求放入选择好的卷的请求队列中——>到达Prediction engine
Prediction engine
Prediction engine采用EBT来预测将来的HL请求。Prediction engine在每次I/O完成之后都更新interval信息,例如,EBT,buffer counter, interval counter, interval distribution
当Write buffer flush或GC出现时,EBT = 当前时间+运行开销(flush/GC所需时间)
NL还是HL判定?
对于传入的I/O请求,预测引擎通过从EBT中减去查询提交时间来计算预测的延迟,Estimated End Time(EET),如果预测的延迟比阈值要小,那么判定为NL,否则HL
framework把预测结果返回给host,包括EET,事件类型等
Latency monitor
SSDcheck监管每个请求的延迟,并将请求分类成NL和HL,然后Latency monitor传递延迟日志和分类信息给Calibrator
calibrator校准器
SSDcheck运行框架动态调整上述的性能模型。校准器接收到延迟日志,并使用延迟日志来检测buffer model
例如,latency monitor注意到HL请求到达校准器,此时若未达到buffer size,当校准器检测到buffer model存在偏差时,它要求prediction engine重置其缓冲区状态。同理,校准器也可以调整GC model
当然,校准器还有其他方面的作用,可以看论文描述
Use case
1.volume-Aware logical volume manager
将一块SSD分成几个逻辑卷,这样使得各卷之间互不干扰
2.prediction-aware I/O scheduler
使用前文提出的ssdcheck‘s prediction engine来通过提高吞吐量和缩减尾延迟而实现更好的OoS性能
1.卷感知逻辑卷管理
**背景:**在云存储系统上使用
多租户共享所带来的尾延迟问题,并使得性能下降。比如读频繁的租户和写频繁的租户共享同一块SSD时,写频繁的负载会导致读频繁的负载变慢,因此改善多租户间的干扰问题十分的重要
采用性能隔离的方式,将一个SSD分成多个逻辑卷,将它们分配给每个租户,以尽量减少干扰
下图显示了传统的分区方案(Linear-LVM)和所提出的方案:
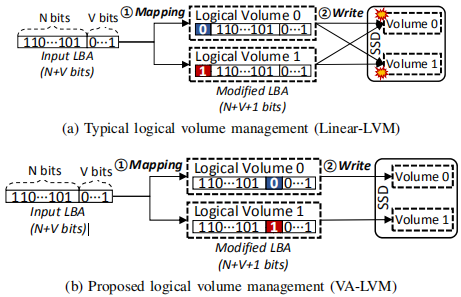
传统的方案在每个卷内部都会发生争用,这大大降低了性能(如图a)
为了减少争用产生,提出VA-LVM。VA-LVM将SSD划分成两个逻辑卷,并将其暴露给host。当host发送一个I/O请求给相关的逻辑卷时,VA-LVM基于每个逻辑卷的ID(eg,0或1)来更新输入的LBA(N+V bits)
VA-LVM将LBA开始的N位+来自volume ID的1位+LBA 后面V位组合起来,最后,VA-LVM将更新的LBA(N+1+V bits)发送I/O请求给SSD,由于第V个位的值表明了具体的逻辑卷号,那么在不同逻辑卷中的I/O请求不会彼此影响
2.预测感知机制(一种基于SSDcheck的I/O调度机制)
有两个不同的版本,一个是传统系统上使用的SSD-only PAS,另一个是使用NVM的新出现系统上使用的Hybrid PAS
SSD-only PAS
目的:减少read尾延迟,增加吞吐量
没有预测感知机制与SSD-only PAS对比
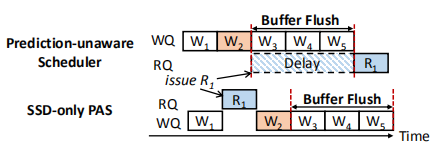
上述事例中,分为两个队列来存放读请求和写请求,WQ和RQ。并此时有请求序列W1-W2,R1,W3-W5。
没有预测感知机制的做法:W2写请求产生一个flush(可能是因为当写入W2写请求时,缓冲区达到阈值,进行flush操作),引起的flush占用NAND,R1需等待(延迟来源)
SSD-only PAS的做法:知道R1将会因为flush而延后,那么通过SSD check可以了解到将R1放在W2前面,通过这样的方式,将延迟要求比较高的read放在可能产生的flush前面执行,可以减少尾延迟,增加吞吐量
SSD-only PAS处理请求的过程如下:
- 如果所有的请求都是read或者write,那么发射最老的请求;否则,SSD-only PAS从SSDcheck中经过延迟预测得到一个最老的read(此种情况我认为是因为可能有flush,那么将read往前推)
- 然后SSD-only PAS使用阈值来区分read是HL还是NL。如果是HL,那么不用管什么顺序,直接发射;否则,发射最老的请求
通过将read 的优先级高于write,可以隐藏buffer flush的开销
Hybrid PAS
——混合型预测感知机制
由于频繁的写入操作所带来的不断flush,使得GC更加的不规则——>采用NVM非易失性存储来解决(但是NVM容量小,满了之后仍然会产生flush,依然不能够解决上述问题)——>采用Hybrid PAS(核心思想:selective delivery)
什么是selective delivery?
- 通过SSDcheck得到延迟预测
- Hybrid PAS将写请求分为NL和HL,Hybrid PAS发送HL给NVM,对于NL请求,基于特定的buffer weight W,随机选择目的地;也就是说,NVM和SSD处理NL请求的W%和(100%-W)%
- 在NVM中的内容周期性的更新
�I want to say�
最近在看一些关于SSD内部操作而引起的延迟抖动问题,包括之前写的I/O determinism,本文的提出的模型旨在于通过预测的方式调整处理请求的先后顺序
整篇文章看了三遍,整理了上述内容,还有如下几个问题未解决:
- 为什么W3~W5在R1前面flush时,不能read(因为Nand被占用)但可以write(写入buffer)?
- write buffer type分为back和fore?有何区别呢?
- 关于权重比W,为何要这么设置呢?
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
good luck!