引子
本工作发表于HPCA 2022,对于3D闪存中制程差异现象,从坏块管理角度出发,解决传统基于P/E次数衡量闪存块生命周期引起的SSD寿命下降。然而考虑单个闪存块的使用情况,又会带来高昂的块故障率。本文发现了物理接近的闪存块具有相似的错误特征,称为Cluster Similarity。从而提出一种基于集群的坏块管理策略,在集群中有一个块在使用时发生故障而标记为坏块时,其余块也将标记为坏块并及时退役。实现不影响可靠性/IO性能的情况下,改善2倍寿命。
本文的集群坏块管理方法可以确保绝大多数块在故障之前被退役(每个集群只有一个闪存块是发生故障而退役的),块故障的原因有很多,包括读写失败/错误率很高,擦除失败。对于故障块需要立即迁移其中的有效数据,确保数据不会丢失。因此,块故障率越高,数据丢失的风险也就越高!
另外,需要注意的是,本文的坏块管理已经不再采用P/E为衡量指标了,而是以集群中是否有块发生故障。
背景
3D闪存架构中的制程差异增加了坏块管理的难度。由于不同块间的错误特征不同,现有的基于P/E次数的坏块管理下,很难确定合适的P/E阈值。若P/E设置激进,则增加数据丢失的可能性;若P/E设置保守,则无法用尽强可靠性的闪存块寿命,从而降低了SSD的使用寿命。本文探讨的是坏块的有效管理,本质是如何权衡可靠性和SSD使用寿命。
动机及基本思想
理想的坏块管理策略是在块失败之前立即退役,关键是能够准确地预测闪存块何时接近其生命周期的末端。所以这篇文章探索了闪存块的物理相似性,从集群退役的方式,当集群中一个闪存块发生故障而作为整个集群报废的指标,这需要探索集群的相似性特征。
对于空间相关性,在之前的工作中已经提出,例如,在一个闪存块的同一层内的相邻字线具有可靠性相似的特性。因此,如果在块级存在空间相关性,那么一个块的失效是其相邻块近期失效的有力指标。本文在海力士3D TLC闪存上进行可靠性实验,分析相邻闪存块之间的错误特征,并且表明存在集群相似性,即物理接近的闪存块具有相似的错误特征。
基于集群相似性,本文提出了一种基于集群的坏块管理策略来改善闪存寿命。集群中的闪存块可靠性及在P/E影响下错误率趋势具有相似性。也就是说,在坏块管理时,当集群中一个闪存块识别为坏块时,集群中其他闪存块均标记为坏块。
注意,这种方法下,对于一个集群,只有一个块是发生故障而标记为坏块,其余块都是没有发生故障而及时标记为坏块。
集群相似性
1.集群相似性的描述
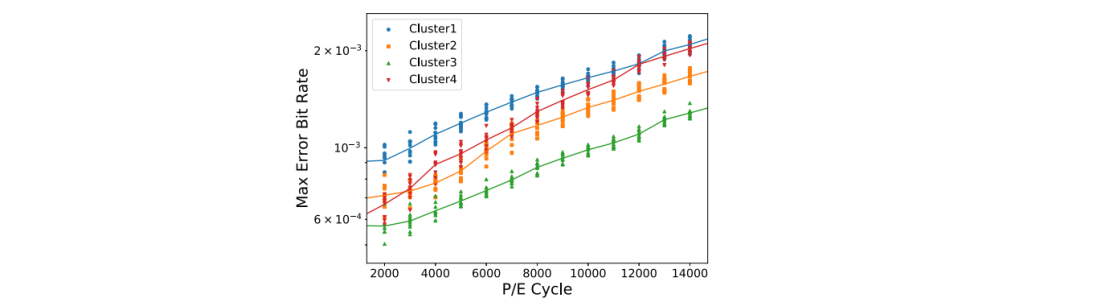
从10个Hynix 3D TLC芯片中收集了40个非重叠集群的错误比特率。每个集群由位于同一Plane上的10个连续的块组成。由于这40个集群错误率分布有些差不多,下图选取四个集群为例。
对于不同集群中的块,在P/E周期中的比特错误率趋势可能非常不同。相比之下,对于同一集群中的块,比特错误率趋势更加相似。
2.量化不同集群大小的相似性
为了分析不同集群大小的相似性,本文提出散度指标来量化集群相似性。评估相邻块对比特错误数的均方根距离RMSD来表示相似性强度;当集群内的所有块完全相同时,集群相似性最强,此时可以推导出公式(4)的参考值公式(5)(见论文);通过将公式(4)中计算的相似度与公式(5)中计算的参考值进行比较,定义为**散度指标**(divergence indicator), Dpage(X,k);当Dpage(X,k)接近于1时,集群具有很强的相似性。Dpage(X,k)值越大,相似性越弱。
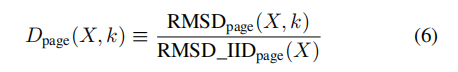
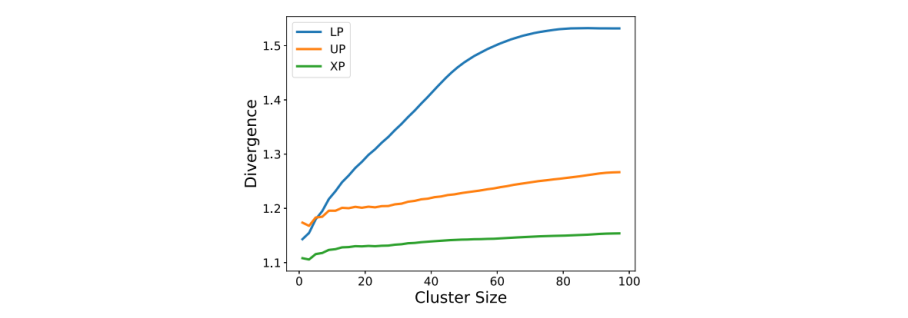
测试集群大小和散度指标之间的关系
下图为散度指标随着cluster size增大的变化趋势。
- 散度指标随着集群大小k的增加而增加。即当集群大小越大,相似性会变弱。
- UP和XP页面比LP有更强的相似性。
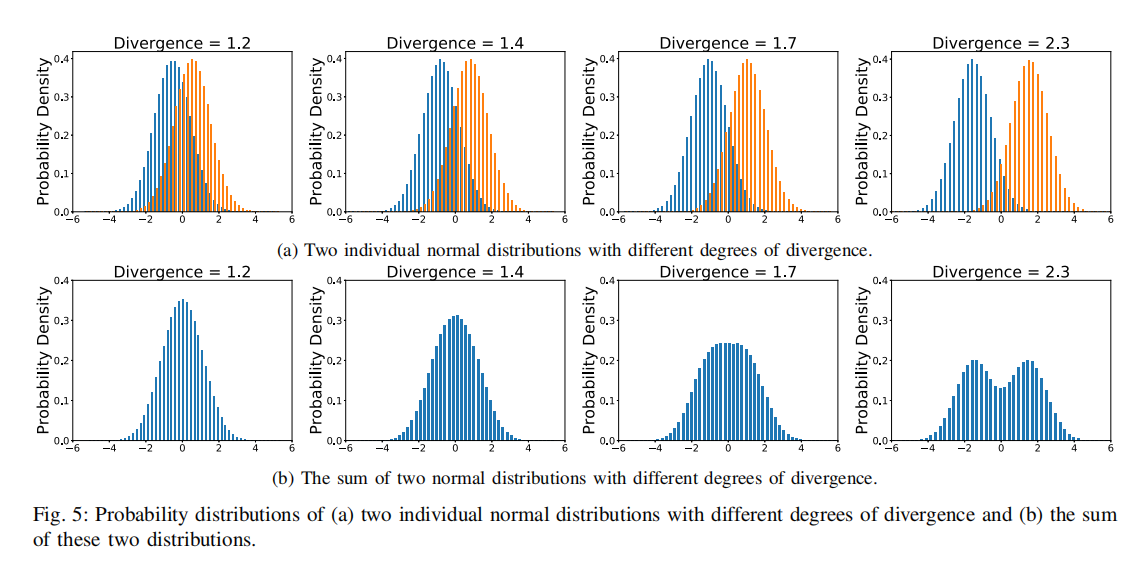
分析不同散度指标的比特错误率分布
图5(a)中,两个波峰分布代表了两组不同块的错误率分布。随着两个错误率分布之间的距离的增加,它们的相似性变弱,散度指标值增大。
图5(b)表示上述两组块错误率分布的叠加求和,可以更清楚观察到相似度强度。
- 当散度指标大于2时,相似性非常弱。具体来说,当散度指标为2.3时,可以看到错误率分布中的两个峰值。散度指标为1.7的分布也有明显不同的形状,有一个平坦的峰值。
- 当散度指标小于1.4时,集群具有很强的相似性。
基于集群的坏块管理
根据集群相似性的发现,本文提出了一种基于集群的坏块管理策略,当其中一个块发生故障时,整个集群将退役。有以下两个关键设计问题:
集群大小的选择。集群大小决定了SSD寿命和可靠性之间的权衡。更大的集群大小会导致更低的故障率(更加保守,并不能完全耗尽每一个闪存块的寿命),但会以更短的SSD寿命为代价。如何选择集群相似度强的集群大小,在不牺牲SSD寿命的情况下保证可靠性,对于基于集群的坏块管理机制的有效性至关重要。为此,我们提出了一个度量标准来量化集群的相似度,并推导出故障率和集群大小之间的相关性。因此,给定集群大小的可靠性和SSD寿命之间的权衡可以被定量地评估。在集群退役时对I/O性能的影响。集群退役的时候,该集群的所有有效数据需要拷贝到其他集群。由于集群退役而导致的读写突发可能会干扰用户的I/O请求。本文提出了一种关键块优先调度方法,只对发生故障块的数据进行及时迁移,集群中其余块的有效数据迁移在SSD空闲时进行。
A.Cluster Size Selection
- 在寿命方面,当散度指标Dpage(X,k)小于1.4时,集群大小具有很强的相似性,这可以作为考虑SSD寿命因素的集群大小选择的指导。
- 在可靠性方面,公式(7)表示了块故障率和集群大小之间的关系。

一旦退役块的数量达到了为OPS而保留的数量,就需要替换SSD。因此,OPS限制了SSD可能遇到的块故障的数量。在基于集群的坏块管理机制中,一旦发生块故障,就会退役整个集群。因此,故障率受到OPS除以集群大小的限制。即,更大的集群大小会导致更低的故障率。
公式(7)获得最大可容忍故障率时,推导出满足此要求的最小集群大小,称为参照集群大小:例如,在现代ssd中,有10%的超额配置率,如果我们决定块故障应该低于或等于0.01,则参考集群大小为10。请注意,实际的数据丢失率低于块故障率,因为数据可以通过底层的数据恢复机制,例如,RAID来恢复。
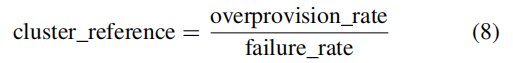
利用散度指标和参考集群大小公式,可以定量评估给定集群大小的可靠性和SSD寿命之间的权衡。例如,如果参考集群大小具有发散指标值≤1.4,我们可以使用集群大小设置来保证不牺牲SSD寿命的期望故障率,这从提出的基于集群的坏块管理中获得了最大的好处。另一方面,如果参考集群大小具有发散指标>1.4,那么我们知道目标故障率是以早期块退役为代价来保证的。
B.Data Reallocation
问题:传统块管理策略中,坏块的重新分配通常被比用户I/O请求具有更高的优先级。所谓坏块的重新分配是指需要将坏块上的有效数据读写出来。此时由于只需要重新分配一个块,通常不会对I/O性能产生重大影响。但是,基于集群的块管理中,以集群为粒度,必须同时退役多个块,在这个过程中,由于大量的读写请求且是突发的,如果此时还按照传统的方式,将此部分的请求优先级高于IO请求,将会影响IO性能。
关键块优先调度策略:当集群中某个块标记为坏块时,该块的数据迁移优先级高于用户请求。集群中其余块在之后SSD空闲时,执行关联的读写操作。因此,可以尽量减少集群退役时的性能影响。
实验测试
实验设置: 从10块海力士TLC闪存选取40个cluster,每个cluster的选取采用同个plane中的连续10个块。对这些块执行编程随机数据,然后执行擦除,循环直到报废。擦除之前数据的dwell time为10s。
实验一:对比基于集群的管理方法和基于块的管理方法
通过block usage和block failure rate表示寿命和故障率。本文设置的OPS为10%,所以纵坐标最大值为0.1。基于块管理的方式,由于坏块都在出现问题才标记为坏块,因此故障率最高可达0.1;而基于集群的坏块管理,集群大小设置为10,即10%OPS可替换坏块的空闲中,仅有1/10的块是发生故障的,其余块都是发生故障之前即使退役了,因此,故障率为0.01;
当P/E次数增加时,块的使用情况和块的错误率都会上升。基于集群的块管理方法中,可以实现23000P/E次数,并实现块故障率为0.01。对于基于块的管理方法,当确保块失败率为0.01时,P/E仅为11000。如果要实现23000P/E,块失败率为0.09。
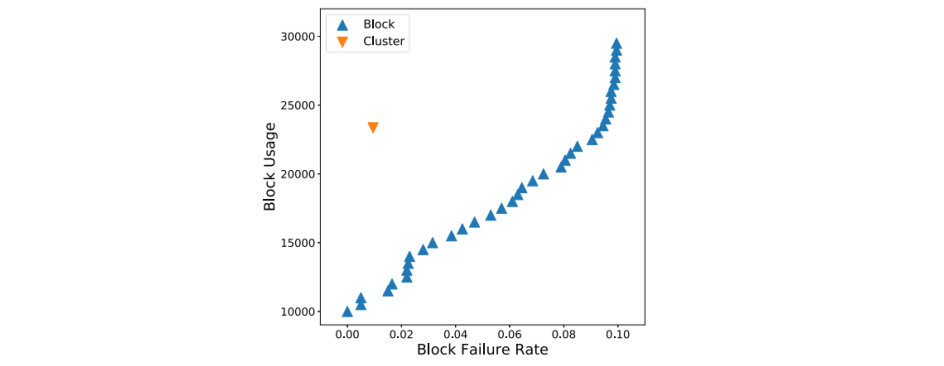
下图可以清楚的看到,随着写入,块退役率(左图)和块故障率(右图)的变化趋势。Block15000和Block20000以P/E为衡量指标,而BlockNoLimit和Cluster以块发生故障为指标。所有的方法下坏块数均不能超过OPS值(10%)。
- 以P/E为衡量指标的两种方法,写入量较低且故障率相对较高
- BlockNoLimit和Cluster的总写入量差不多,但是Cluster能保持较低的故障率
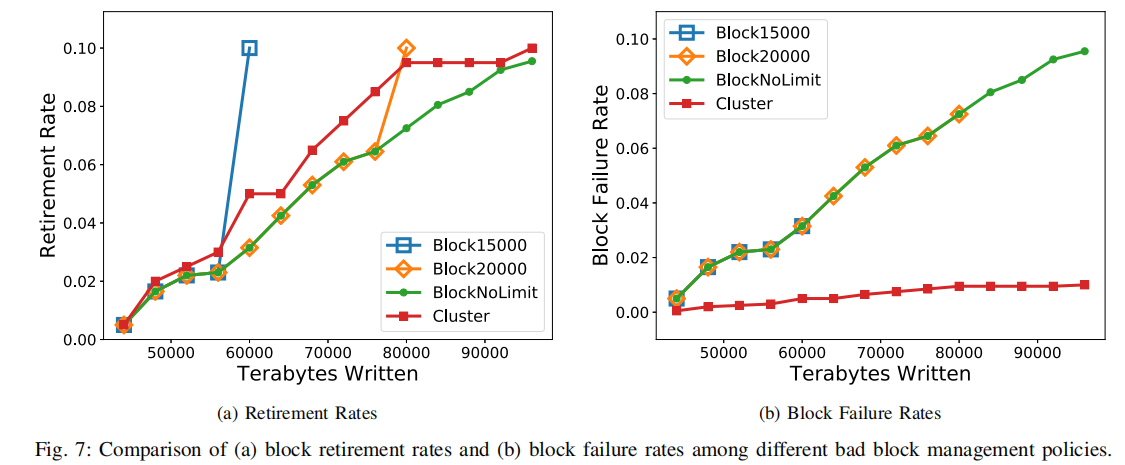
不同的集群大小如何影响基于集群的管理策略?
图8展示了块退休率和块故障率随时间变化趋势。评估了五种不同的集群大小,包括1、2、5、10,以及clusterAll表示同一芯片内的所有块视为单个集群。注意,cluster1相当于BlockNoLimit,clusterALL代表集群很大。
- 图8(a),当集群大小增加时,寿命降低。然而,对于集群大小为1、2、5、10,差异不显著。这是因为,如图4所示,当集群大小等于10时,集群相似性仍然很强。
- 图8(b),随着集群大小的增加,块故障率减小。然而,当集群大小等于10时,块故障率已经小于0.01。因此,没有必要选择一个更大的集群大小。
实验二:测试数据重新分配的性能情况
图9为块退役前后的I/O延迟,可以看到集群退役确实会对性能产生影响,通过提出的criticalReAlloc可以有效解决此问题。
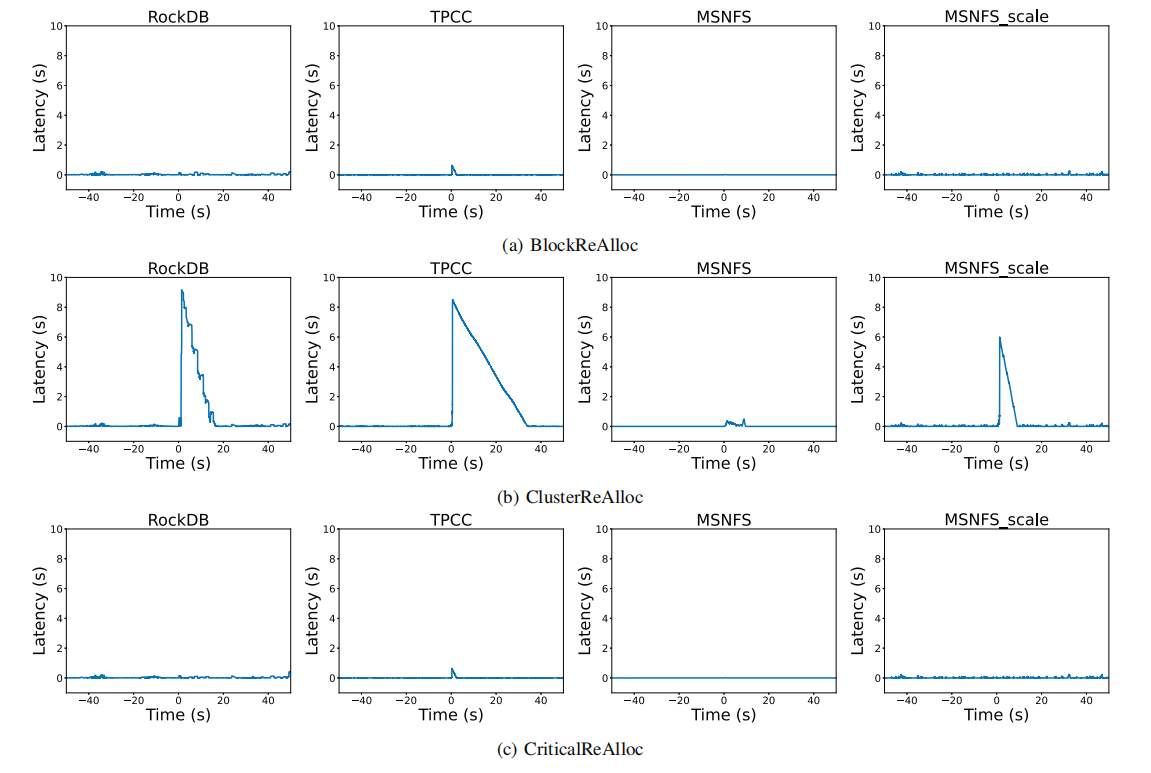
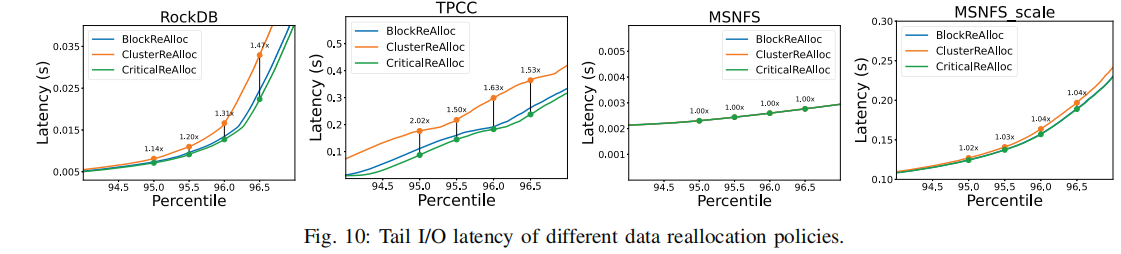
图10显示了不同负载的尾端延迟,对尾部延迟的影响与负载的I/O密集度紧密相关。I/O越密集,集群退役对性能影响越大。
criticalReAlloc与BlockReAlloc相当,甚至略好。当应用criticalReAlloc时,只有故障块的重新分配可能会延迟用户的I/O请求,其他块只在SSD空闲时进行重新分配。而BlockReAlloc中,SSD报废前每一个块失败时,都可能影响用户I/O请求。
总结
- 本文通过实验分析相邻闪存块之间的误差特征,并表明在一个真实的平台(即Hynix 3D TLC闪存芯片)上存在集群相似性。进而提出一种基于集群的坏块管理方式,能够确保闪存可靠性的前提下,提升闪存寿命。
- 考虑到基于集群的管理方式下,由于集群退役引起的I/O性能问题,本文还提供了一种针对坏块重新分配的关键块优先调度方法。实验结果表明所提出的方法可以延长闪存寿命2倍,而不会有任何I/O性能下降。
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
good luck!