Generating Realistic Wear Distributions for SSDs
本文发表于HotStorage 22,来自韩国 Bryan S. Kim团队
【背景】由于固态硬盘随着使用磨损等会出现老化现象,从而导致闪存数据错误率增加而影响性能。因此,理解老化现象对闪存研究非常重要。
【问题】然而现有开发工具(如Amber、FEMU和MQSim)并没有在其设计中考虑老化现象。
现有做法是:
1.通过预处理进行老化是非常耗时的,因为需要多年的模拟时间才能达到需要的老化状态。
2.将初始擦除次数设置为更大的非零值,但这是一种不现实的磨损状态,因为现代SSD甚至不能有效地通过均衡磨损保障闪存块都保持相同的擦除计数 [FAST 22,Operational Characteristics of SSDs in Enterprise Storage Systems: A Large-Scale Field Study]。
如何生成闪存未来的磨损状态呢?
【方法】本文提出Fast-Forwardable SSD(FF-SSD),一种基于机器学习的SSD老化框架,可以产生具有代表性的未来磨损状态。在一个典型的SSD模型中,许多组件执行重复的工作。例如,GC可能会在一段时间内不断地选择几个热块作为victim块。同样,在SSD的生命周期内,定期计算WL的触发条件。因此,可以从过去的执行中学习到SSD内的行为,以预测未来的SSD的内部状态。
FF-SSD 已开源:https://github.com/ZiyangJiao/FF-SSD.
【挑战】使用机器学习方法对 SSD 内部状态进行在线、细粒度推断的挑战是双重的。
- 推理必须准确。现代SSD是复杂的嵌入式系统,通过垃圾回收、磨损均衡、错误处理和数据清理等后台操作来管理所有内部资源。需要学习这些内部复杂性以使推理高度准确。
- 相对于模拟时间,推理必须快速有效。否则,它要么带来微不足道的好处,要么甚至延长整个过程。卷积神经网络或循环神经网络等深度学习模型会引入更多复杂性,并可能导致训练和推理性能下降。
为了解决这些问题,FF-SSD 逐步为每个块构建轻量级回归模型,以捕捉SSD内部状态的变化,并使用过去执行的信息预测它们的轨迹。
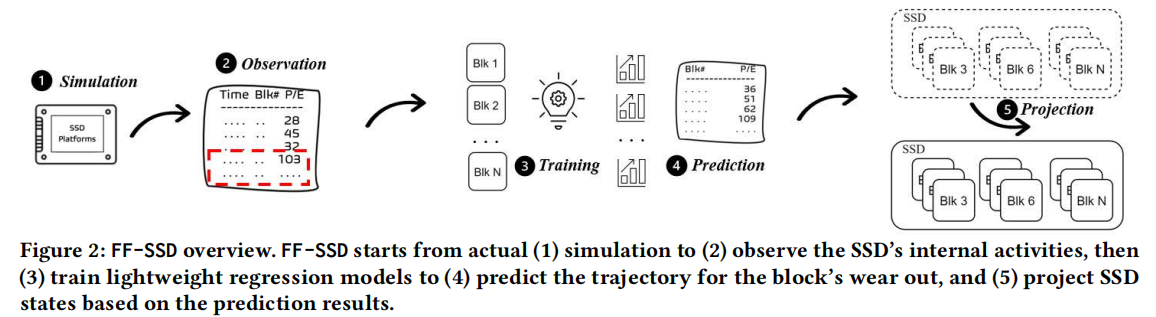
【FF-SSD最终效果】
1.通过生成与完整模拟结果匹配高达99%的真实分布;
2.通过将模拟加速2倍以达到所需的老化状态来提高效率;
3.可以集成到多个平台,实现模块化。
【实验评估】
测试使用跨多个平台的实际工作负载评估FF-SSD,以证明 FF-SSD对SSD老化的有用性。
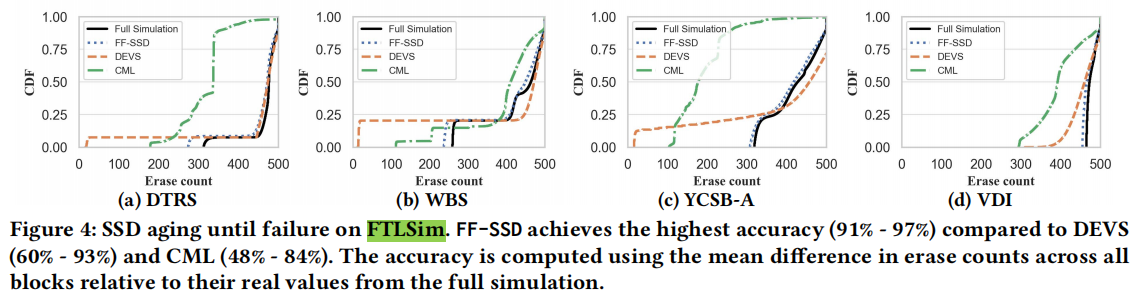
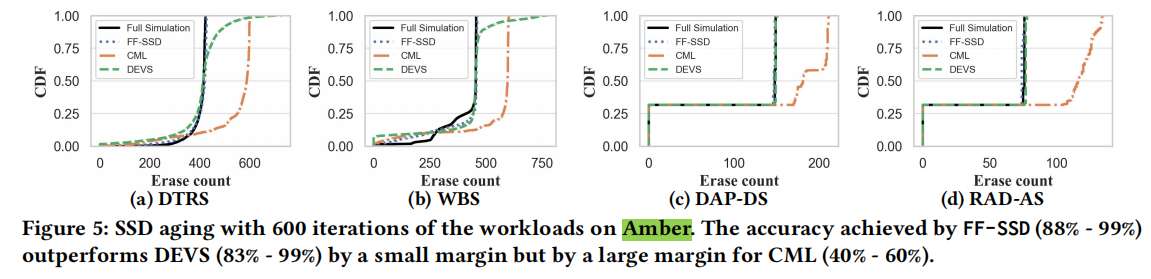
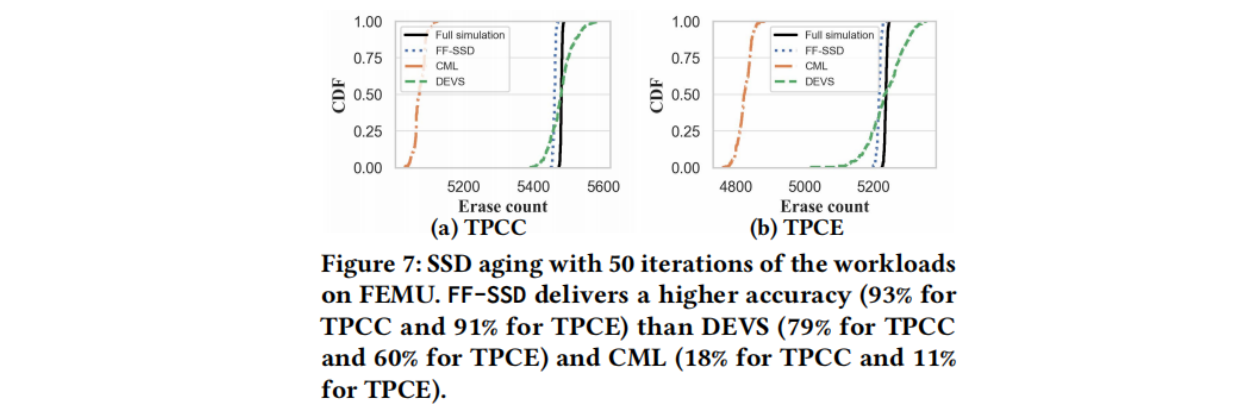
Full Simulation是实际模拟的结果;DEVS和CML是现有工作,但都不是为SSD老化而设计的,并且忽略了现代SSD的复杂性。
1.FF-SSD的有效性测试
(1)FTLSim
(2)Amber
(3)FEMU
2.有效性和准确性之间的权衡
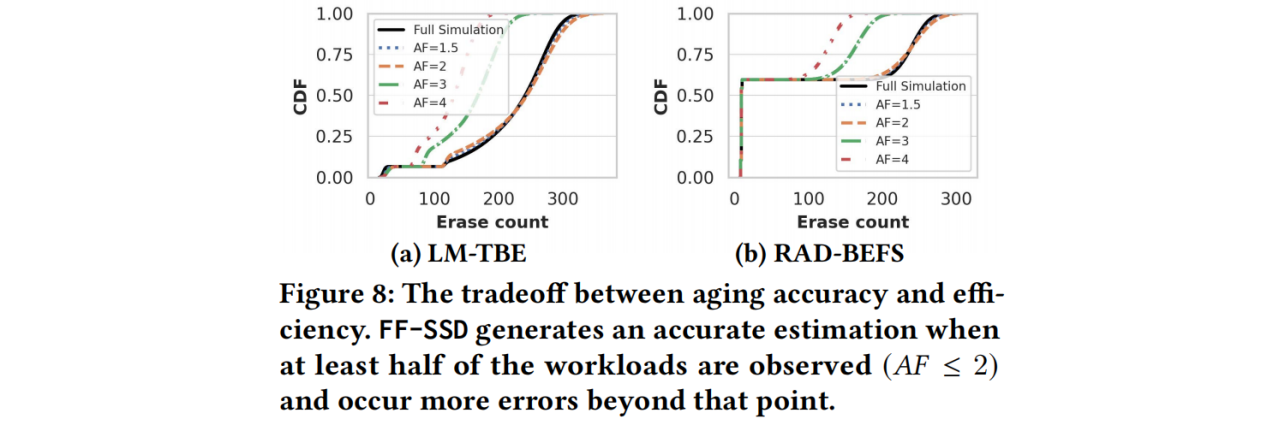
定量分析不同的加速因子(1.5、2、3和4)如何影响整体准确性,然后提供一个保守的AF来权衡。并生成在FTLSim上运行100次迭代的LM-TBE和MSN-BEFS工作负载的磨损状态。总体而言,AF = 1.5和AF= 2的准确度相似,而当AF大于2 时,准确度明显下降。特别是,对于LM-TBE,准确度范围为56% (AF = 4 ) - 91% (AF = 1.5)。从AF = 1.5到AF = 2,准确度降低了4%,而从AF = 2 到AF = 3 降低了19%。同样,对于RAD-BEFS,准确度为98%(AF = 1.5)和97%(AF = 2),AF=3的准确率降低了13%,AF=4为20%。
根据上述实验结果,当观察到至少一半的工作负载(AF≤2)时,FF-SSD产生了一个准确的分布,而对于AF大于2时,可能会发生更多的错误,导致预测不准确。
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
good luck!