写在文前
在学习这篇文章前,先来了解下块设备层中Multi-Queue的概念,Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems,这篇文章于2013年发在SYSTOR,首次提出了multi-queue,从Linux5.0开始就成为块设备层的默认选项,介绍 Linux 内核的块设备层针对现代硬件——高速 SSD、多核 CPU(NUMA)的新设计
Single-Queue
起初的块设备层是针对HDD设计的,我们知道,HDD的I/O性能并不好,而论文中提到当时块设备层可以支持百万级IOPS,这对于HDD来说是完全够用的。因此,以前的很多研究都在于改善底层硬件的性能,而不是内核。但是随着SSD的发展,速度越来越快,原先的设计并不能很好的满足高性能SSD和多核CPU的需求,因此文章提出了Multi-Queue的想法。
下图是单队列的架构:
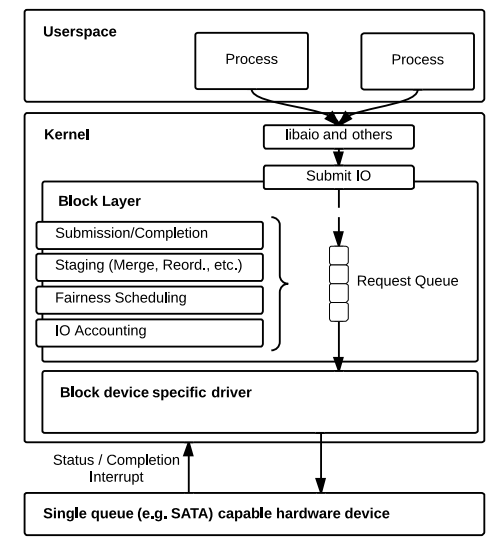
Request Queue 全局共享,由一个锁进行保护。所有对 Request Queue 的操作,如加入/移除一个 I/O 请求,I/O 合并,I/O 重排序,I/O 调度等,都需互斥操作
显然,上述限制对于现代的设备来说怎么能容忍呢?极大的限制了性能的提升,也就是应用层和设备层速度都很快,然而夹在中间的块设备层无法满足上下两层的交互需求了
因此可以总结如下:
- HDD速度很慢,使用一个全局队列完全可以满足需求
- CPU核数少,竞争锁的现象不严重
- 一个全局队列便于操作和管理
Multi-Queue
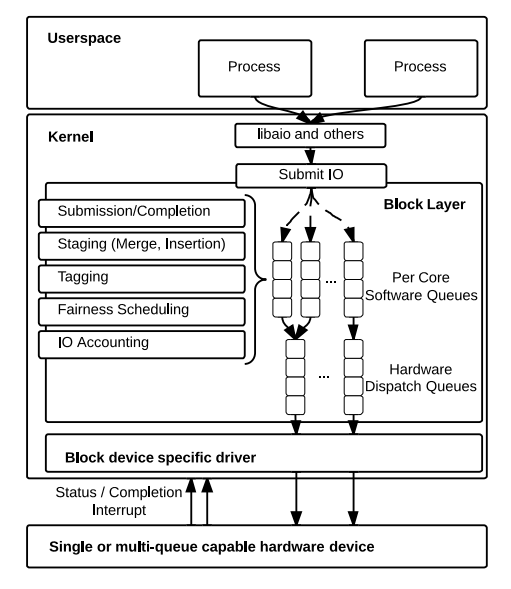
原来的全局请求队列主要有两个功能:
- I/O 调度(包括 I/O 合并、I/O 重排序等优化)
- 限流,避免硬件设备过载
在多队列中,分为以下两个部分实现:
软件队列: 负责 I/O 的调度和优化,可为每个核或者每个socket配置一个处理队列。假设一个NUMA系统有4个sockets,每个socket有6个核,那么最少可配置4个软件队列,最多配置24个软件队列。在对应的每个软件队列中可进行请求调度,添加标记以及计数等功能。在此基础上,每个socket或者核直接将请求发送至其对应的软件队列中, 从而可避免单请求队列造成的锁竞争问题。
硬件队列:硬件队列主要负责与底层设备驱动的匹配,即存在多少个设备驱动,则配置对应数量的硬件队列。负责将来自软件队列的请求发送至驱动层
因此,软件队列中存放来自上层的请求,这些请求是还未被发送到具体设备的请求;而每个硬件队列由于对应一个设备驱动,因此,在硬件队列中的请求是已经发送到相应设备的请求
参考资料:linux-块设备层中的multi-queue-分析
Linux Multi-Queue Block IO Queueing Mechanism (blk-mq)
Linux kernel 5.0+ switching to Multi-Queue Block as default
问题解决
Classical Fair Queueing
flow:每个流由到达路由器或服务器的一系列请求/数据包组成
request:每个请求都有相应的cost
fair queuing指的是根据流的权重来分配资源
活动流(active):有一个或多个请求尚未处理
积压流(backlogged):有尚未处理的请求还未派遣dispatch给设备
Fair queuing algorithms:根据活动流的权重来消耗剩余资源,并且如果一个流的请求到达速度慢,不至于形成积压流,那么这个流未消耗的资源可以被部分回收
Start-time Fair Queuing(SFQ)
在每个请求到达的时候,标记开始时间和完成时间,并且按照开始时间分发请求。这里的标记值表示资源使用历史记录中的每个请求应根据虚拟时间的系统概念
如果满足
- 所有的流都被积压
- 服务器以固定的理想速度完成工作
- 请求成本可以精确的度量服务时间
- 权重与服务能力相加
那么虚拟时间总是单调前进,并和实际时间一致
当服务器空闲时,虚拟时间被定义为等于该时间服务的任何请求的最大完成标记。
Parallel Dispatch
具有内部并行性的服务器可以同时处理多个请求,因此在此场景下,对于常规的SFQ,(1)虚拟时间不是很好的定义(2)即使是活动流也可能在资源利用率方面落后,如果它生成的并发请求数量不足,那么就无法使用其分配的份额
SFQ(D)的工作原理和SFQ相同,但是允许最多D个服务请求,当D=1时,退化为SFQ
由于无序完成,虚拟时间被计算为未完成的(尚未发送的)请求的最小值或发送请求的最大值
Multi-Queue Fair Queueing
主要是障碍是:(1)多队列I/O的架构只有一个优先队列对其排序 (2)需要同时发送多个请求,并且无法简单地依据虚拟时间,会出故障

为了保证各个队列的公平性,我们挂起任何队列,其领先请求是最慢的积压流的第一个(确定虚拟时间的队列)提前超过某个预定义的阈值T,从而允许其他队列先处理
通过适当调整T,我们可以找到一个设计点来提供传统公平排队的大部分公平性和完全独立队列的大部分性能。
对于内部并行设备,我们通常需要在前一个请求完成之前发送一个新请求,以使设备处于繁忙状态。同时,由于设备决定发送请求的顺序,我们通常必须避免发送比实际并行处理的请求更多的请求,从而保持了我们命令这些held-back requests延迟请求的能力。
对于任何支持D≥2并发请求的设备:不再保证活动流至少使用被分配到的公平资源
在传统的公平排队系统中,活动流决定了虚拟时间的进程。在并行设备下,不饱和的活动流中空闲资源将被回收分配给其他流。积压流来决定虚拟时间
定义每个流的虚拟时间:
队列中存放的请求是已经被提交但是还未发送给设备,根据定义提交这些请求的流是积压流。对于每个这样的流f,其虚拟时间被定义为f的第一个(最老的)积压请求(等待发送)的开始标记。注意到流f可能在多个队列中有积压请求
假设流f有多个挂起请求,那么发送第一个请求将会增加流f的虚拟时间,l/r,其中r是流f 的权重,l是请求的长度
对于某些设备,我们也可以根据操作类型缩放“大小”,例如,为了反映写入比ssd上的读取更昂贵这一事实。
我们定义全局虚拟时间是所有积压流中每个流虚拟时间的最小值。
一旦流量变得滞后,它就会停止对虚拟时间做出贡献,无论滞后流中是否缺乏活动,虚拟时间都可能会提前
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
good luck!