SSD内部的GC导致性能的下降和吞吐量的波动,这极大的影响实时系统的QoS
在FLASH存储器中满足QoS要求有三大挑战:
- 在共享一个FLASH子系统时,多个FTL任务之间存在资源争用
- 任务的关键程度取决于存储系统的状态。当系统的空闲块数量较少时,垃圾收集的性能就成为瓶颈,因为需要为主机写入回收空间
- 由于垃圾回收引起的负载不均衡
针对上述问题,本文讲述了三方面的特征:1. FTL任务之间公平地调度闪存操作 2. 根据系统的状态,动态调整FTL任务之间的占比 3. 平衡所有chip的负载(对一些non-binding requests,动态调整写入的chip,以平衡chip之间的负载均衡)
QoS-aware flash memory controller (QoSFC)
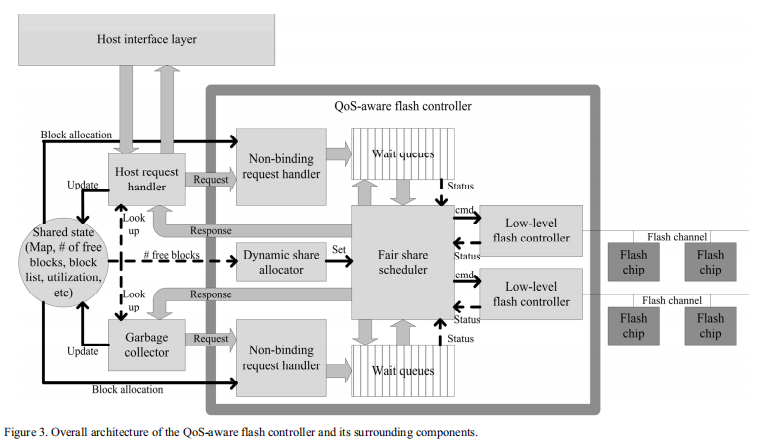
为了充分利用现有SSD上的嵌入式处理器,host stream和GC stream并发执行。所谓host stream就是从Host request handler发出的,而GC stream是从Garbage collector发出的。stream ID标记在每个请求上
Fair Share Scheduler
根据stream的权重对请求进行调度
FSS:
- 追踪channel和chip的状态和有效性
- 基于fair share决定哪些请求在队列中等待
- 向LLFC发出命令并接收响应
LLFC:处理到闪存芯片的IO活动和物理信号,并向FSS隐藏许多NAND闪存命令、地址、数据周期和时间细节。
virtual time:工作值(操作延迟)/所属流的权重;因此含有更高权重的流所得的虚拟时间增加得更慢,这样就比其他流运行得更为频繁。故其可以控制流的速度,因此可以根据 virtual time来调度
每当来自两个流的请求争夺共享资源(channel或chip)时,FSS选择stream进展最少的请求,也就是选择虚拟时间小的流中的请求进行处理
下面来看一个例子:
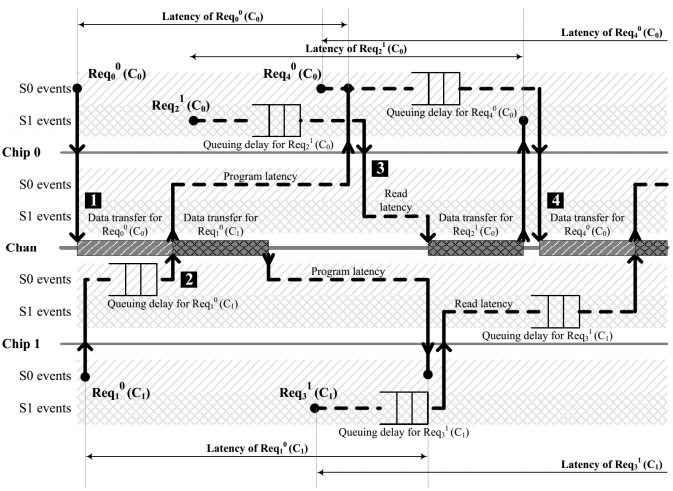
$\operatorname{Req}{i}^{\mathrm{S}}\left(\mathrm{C}{\mathrm{n}}\right)$表示来自stream S到chip n中的第i个请求
需要注意的是当请求到达时,若channel和chip都空闲,那么直接执行;如果有请求正在处理,那么进入channel队列,并且局部虚拟时间的计算为队列前面请求预计完成时间的总和
Dynamic Share Allocator
根据系统状态对流权重进行动态调整
当空闲块充足时,host stream的权重应该更高;当空闲块不足时,GC stream的权重应该更高
因此,DSA使用系统中的空闲块数作为feedback,通过一个简单的PID controller来控制流的权重
在t时刻,DSA计算误差值e(t)和控制变量u(t)如下:
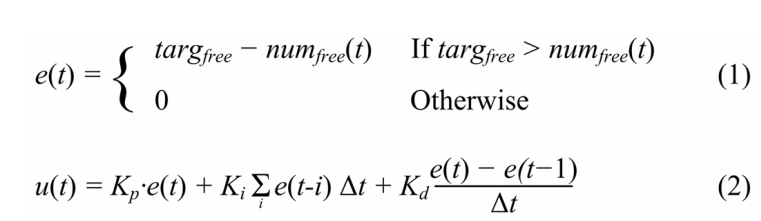
其中targfree是空闲块的目标数目,numfree(t)是时间t处的空闲块数,kp、ki和kd是控制系数。
从而,可以得到host stream和GC stream为
$w_{H O S T}=\frac{n u m_{f r e e}(t)}{n u m_{f r e e}(t)+u(t)} \quad w_{G C}=1-w_{H O S T}$
Non-binding Request Handler
均衡chip之间的负载
根据每个芯片的估计排队延迟,动态分配用于写入请求的目标chip,选择最小延迟的chip:
- 给定 stream ID S
- 估计队列延迟 $d^{q} m, n$,表示stream m ,chip n上所有操作的延迟总和
- chip n上当前请求的估计完成时间 $t^{c p l}_{n}$
下述方程表示chip n中估计完成时间和归一化估计队列延迟之和为最小
$\operatorname{argmin}{n}\left(t^{c p l}{n}+\sum_{i} \frac{w_{i}}{w_{S}} \cdot d^{q}_{i, n}\right)$
在最坏的情况下,如果来自竞争流的请求被连续调度,则无法保证请求何时可以启动。因为NRH不能提前知道实际的调度顺序
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
good luck!