本文是2017年FAST上的一篇paper,通过避免GC-blocked I/Os来消除GC所带来的尾端延迟。
问题引入
SSD并不总是能满足用户期待的性能要求,这正是因为尾端延迟存在。why is hard to meet SLAs with SSD?
一个首要的原因就是GC的影响,导致性能的不稳定。由于SSD自身的废旧地更新特点,在使用一段时间之后,系统内部的空闲资源越来越少,这就需要通过GC来回收无效资源。而GC触发时,由于SSD控制器被占用,不能服务用到来的I/Os,因此队列中的I/Os被阻塞。这会带来严重的长延迟,从而影响整体性能。
目前很多工作是从减少GC的次数入手,但这些方法只是降低了产生这种情况的概率,并没有从根本上去解决。因此本文提出GC-tolerant SSD,从根本上消除了GC带来的long-latency,使得性能保持稳定。——称作TTFlash
策略
RAIN
本文的技术基于RAIN的概念
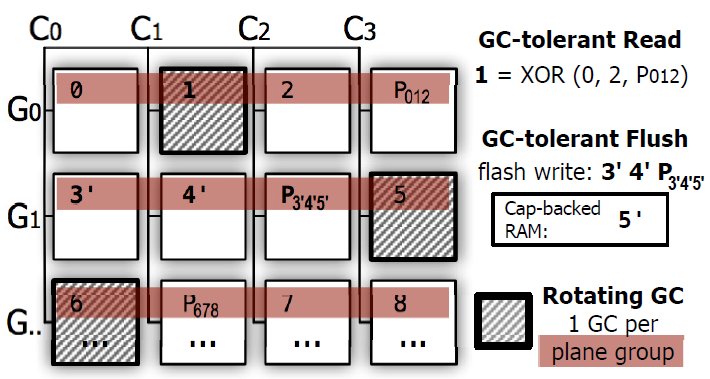
如上图所示,每个channel相同的位置组成一个条带,一个条带也就是一个plane-group。在每个条带上,根据逻辑地址,相当于每n-1个pages分配一个parity page。这样既可实现当一个条带上的一个plane正在做GC操作时,可以通过其他页和parity page计算出来,从而不需要等待。
并且这些parity page是交错着放置,确保hot parity page均匀分布,因此可以实现每个channel的公平性。
此图中,C0-C3表示通道,可以是8channel,16channel,32channel
每个channel上挂着多个芯片,每个channel上对应的芯片号组成一个芯片组,也叫一个stripe。对于每个芯片组中,对应的四个页中,其中一个页为奇偶校验页。
我们根据逻辑地址LPN,那么逻辑地址0,1,2号产生一个校验页为P0,1,2存入剩余的一个页
这样如果碰到一个页出错了,那么可以通过其余三个页计算出来
本文提出了四个改进点,实现block-level的部分页并行读取操作。
GC所导致的阻塞分为以下几种:
1)controller-blocking
2)Channel-blocking
3)plane-blocking
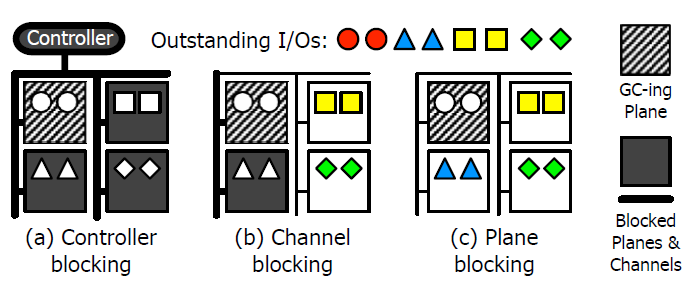
1.Plane-Blocking GC(PB)
原先一个plane中的block被选中做GC时,其余plane也不能服务I/O请求,这就是controller-blocking。从图中可以感受到,Channel-blocking比controller-blocking要好,因为当一个plane正在做GC操作时,当前plane所在的channel被阻塞了,但是其他channel上的I/O请求还是可以被服务的。但是我们来考虑一下大请求,当一个请求所要读取的数据位于不同的channel上,很可能页位于正被阻塞的channel上,那么此请求仍然不能很好的被处理。而PB则将阻塞控制在一个更为细粒度的plane,因此可以在一定程度上降低GC所带来的性能波动。
PB虽好,但也没有完全解决为延迟的问题,处于plane-blocking上的I/O仍不能被服务,要等到当前plane GC完成后才能被处理。
还有一个值得注意的问题是,随着SSD容量的不断增加,要实现一次GC操作就需要花费更长的时间,因此所带来的延迟也就越长。并且上述方式所带来的另一个问题是当plane需要controller发布下一条命令时,controller可能正在服务于其他channel,那么这也会带来延迟。
2.GC-Tolerant Read(GTR)
通过上述方法可以实现GTR,我们计算下开销,parity的计算需要花费3微妙(N小于等于8),额外的parity读取花费40+100微妙,但是这边考虑是读取条带上的所有page,如果只读取少量page,俺么这种方法并不是很好,这需要将其他所有page都读取出来,然后计算出被阻塞的页。因此,我们通过计算GC完成所需要的时间,如果大于上述方法的时间开销时,才采用上述GTR。
3.Rotating GC(RGC)
每个方法都有其不足之处,上述方法仍未解决本质问题。one parity can only cut “one tail”. Double-parity RAIN is not used due to the larger space overhead.
rotating GC depends on our RAIN layout that ensures every stripe to be statically mapped to a plane group.
4.GC-Tolerant Flush(GTF)
在GC过程中解决写请求的尾端延迟问题,通过buffer,将写请求先缓存起来,然后再通过flush的方式写入ssd。当缓冲区占用率超过80%时,后台刷新将运行以删除某些页面。当缓冲区已满(例如,由于大量的大写入),前台刷新将运行,这将阻止传入写入,直到某些空间被释放。这就会产生严重的尾端延迟
并且在更新数据的时候需要重新计算校验页
GC-Tolerant Flush解决的方法是
- 当一个条带中所有的数据都需要更新时,对于没有被GC占用的plane可以直接写入,对于正在GC的plane,需要等待GC执行完成后才可写入,因此如果缓冲区满了,可以先更新不在GC状态的页,这样的话,其实需要的buffer空间并不大
- 如果更新一个组中的部分页,例如更新7和8,那么还需要更新校验页,需要把被GC占用的6号页也读取出来,原先要读取的话必须等待GC完成后才可以。但是通过上面讲述的GC-Tolerant方法,可以直接计算出6号页,并且结合7和8计算出新的校验页。
通过上述四个策略,本文提出的最优方案可以将尾端延迟控制在极小范围内,只留下一个小尾巴

“I want to say”
这篇文章是解决GC所导致的尾端延迟,当然在实际过程中,导致尾端延迟的因素有很多个,包括我之前研究的课题LDPC引起的延迟波动,这类话题可以从降低这些情况的概率入手,也可以从避免碰到这类情况入手,当然本质上很难解决,但是在一定程度上通过采取某些措施是可以大大改进性能的!如何才能想到更好的idea来解决,当然是要集思广益啦,读完这篇paper,感觉做学术研究真的还是要一步一步,step by step,针对前一种策略想到后一种策略,继而后一种新的策略又存在新的问题,那么就要继续在此基础之上提出新的策略。可以看到很多paper的实验对比都是这样的。
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
good luck!